Dogen v1.0.25, "Foz do Cunene"
River mouth of the Cunene River, Angola. (C) 2015 O Viajante.

Introduction
Another month, another Dogen sprint. And what a sprint it was! A veritable hard slog, in which we dragged ourselves through miles in the muddy terrain of the physical meta-model, one small step at a time. Our stiff upper lips were sternly tested, and never more so than at the very end of the sprint; we almost managed to connect the dots, plug in the shiny new code-generated physical model, and replace the existing hand-crafted code. Almost. It was very close, but, alas, the end-of-sprint bell rung just as we were applying the finishing touches, meaning that, after a marathon, we found ourselves a few yards short of the sprint goal. Nonetheless, it was by all accounts an extremely successful sprint. And, as part of the numerous activities around the physical meta-model, we somehow managed to also do some user facing fixes too, so there are goodies in pretty much any direction you choose to look at.
So, lets have a gander and see how it all went down.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
Video 1: Sprint 25 Demo.
Profiles do not support collection types
A long-ish standing bug in the variability subsystem has been the lack of support for collections in profiles. If you need to remind yourself what exactly profiles are, the release notes of sprint 16 contain a bit of context which may be helpful before you proceed. These notes can also be further supplemented by those of sprint 22 - though, to be fair, the latter describe rather more advanced uses of the feature. At any rate, profiles are used extensively throughout Dogen, and on the main, they have worked surprisingly well. But collections had escaped its remit thus far.
The problem with collections is perhaps best illustrated by means of an example. Prior to this release, if you looked at a random model in Dogen, you would likely find the following:
#DOGEN ignore_files_matching_regex=.*/test/.*
#DOGEN ignore_files_matching_regex=.*/tests/.*
...
This little incantation makes sure we don't delete hand-crafted test files. The meta-data key ignore_files_matching_regex is of type text_collection, and this feature is used by the remove_files_transform in the physical model to filter files before we decide to delete them. Of course, you will then say: "this smells like a hack to me! Why aren't the manual test files instances of model elements themselves?" And, of course, you'd be right to say so, for they should indeed be modeled; there is even a backlogged story with words to that effect, but we just haven't got round to it yet. Only so many hours in the day, and all that. But back to the case in point, it has been mildly painful to have to duplicate cases such as the above across models because of the lack of support for collections in variability's profiles. As we didn't have many of these, it was deemed a low priority ticket and we got on with life.
With the physical meta-model work, things took a turn for the worse; suddenly there were a whole lot of wale KVPs lying around all over the place:
#DOGEN masd.wale.kvp.class.simple_name=primitive_header_transform
#DOGEN masd.wale.kvp.archetype.simple_name=primitive_header
Here, the collection masd.wale.kvp is a KVP (e.g. key_value_pair in variability terms). If you multiply this by the 80-odd M2T transforms we have scattered over C++ and C#, the magnitude of the problem becomes apparent. So we had no option but get our hands dirty and fix the variability subsystem. Turns out the fix was not trivial at all, and required a lot of heavy lifting but by the end of it we addressed it for both cases of collections; it is now possible to add any element of the variability subsystem to a profile and it will work. However, its worthwhile considering what the semantics of the merging mean after this change. Up to now we only had to deal with scalars, so the approach for the merge was very simple:
- if an entry existed in the model element, it took priority - regardless of existing on a bindable profile or not;
- if an entry existed in the profile but not in the modeling element, we just used the profile entry.
Because these were scalars we could simply take one of the two, lhs or rhs. With collections, following this logic is not entirely ideal. This is because we really want the merge to, well, merge the two collections together rather than replacing values. For example, in the KVP use case, we define KVPs in a hierarchy of profiles and then possibly further overload them at the element level (Figure 1). Where the same key exists in both lhs and rhs, we can apply the existing logic for scalars and take one of the two, with the element having precedence. This is what we have chosen to implement this sprint.

Figure 1: Profiles used to model the KVPs for M2T transforms.
This very simple merging strategy has worked for all our use cases, but of course there is the potential of surprising behaviour; for example, you may think the model element will take priority over the profile, given that this is the behaviour for scalars. Surprising behaviour is never ideal, so in the future we may need to add some kind of knob to allow configuring the merge strategy. We'll cross that bridge when we have a use case.
Extend tracing to M2T transforms
Tracing is one of those parts of Dogen which we are never quite sure whether to consider it a "user facing" part of the application or not. It is available to end users, of course, but what they may want to do with it is not exactly clear, given it dumps internal information about Dogen's transforms. At any rate, thus far we have been considering it as part of the external interface and we shall continue to do so. If you need to remind yourself how to use the tracing subsystem, the release notes of the previous sprint had a quick refresher so its worth having a look at those.
To the topic in question then. With this release, the volume of tracing data has increased considerably. This is a side-effect of normalising "formatters" into regular M2T transforms. Since they are now just like any other transform, it therefore follows they're expected to also hook into the tracing subsystem; as a result, we now have 80-odd new transforms, producing large volumes of tracing data. Mind you, these new traces are very useful, because its now possible to very quickly see the state of the modeling element prior to text generation, as well as the text output coming out of each specific M2T transform. Nonetheless, the incrase in tracing data had consequences; we are now generating so many files that we found ourselves having to bump the transform counter from 3 digits to 5 digits, as this small snippet of the tree command for a tracing directory amply demonstrates:
...
│ │ │ ├── 00007-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-input.json
│ │ │ ├── 00008-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-output.json
│ │ │ ├── 00009-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-input.json
│ │ │ ├── 00010-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-output.json
│ │ │ ├── 00011-text.transforms.model_to_text_chain
│ │ │ │ ├── 00000-text.transforms.model_to_text_chain-dogen.cli-bdcefca5-4bbc-4a53-b622-e89d19192ed3-input.json
│ │ │ │ ├── 00001-text.cpp.model_to_text_cpp_chain
│ │ │ │ │ ├── 00000-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-input.json
│ │ │ │ │ ├── 00001-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-output.json
│ │ │ │ │ ├── 00002-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-input.json
│ │ │ │ │ ├── 00003-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-output.json
│ │ │ │ │ ├── 00004-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-input.json
│ │ │ │ │ ├── 00005-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-output.json
│ │ │ │ │ ├── 00006-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-input.json
│ │ │ │ │ ├── 00007-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-output.json
│ │ │ │ │ ├── 00008-text.cpp.transforms.types.class_implementation_transform-dogen.cli.conversion_configuration-d47900c5-faeb-49b7-8ae2-c3a0d5f32f9a-input.json
...
In fact, we started to generate so much tracing data that it became obvious we needed some simple way to filter it. Which is where the next story comes in.
Add "scoped tracing" via regexes
With this release we've added a new option to the tracing subsystem: tracing-filter-regex. It is described as follows in the help text:
Tracing:
...
--tracing-filter-regex arg One or more regular expressions for the
transform ID, used to filter the tracing
output.
The idea is that when we trace we tend to look for the output of specific transforms or groups of transforms, and so it may make sense to filter out the output to speed up generation. For example, to narrow tracing to the M2T chain, one could use:
--tracing-filter-regex ".*text.transforms.model_to_text_chain.*"
This would result in 5 tracing files being generated rather than the 550 odd for a for trace of the dogen.cli model.
Handling of container names is incorrect
The logical model has many model elements which can contain other modeling elements. The most obvious case is, of course, module, which maps to a UML package in the logical dimension and to namespace in the physical dimension for many technical spaces. However, there are others, such as modeline_group for decorations, as well as the new physical elements such as backend and facet. Turns out we had a bug in the mapping of these containers from the logical dimension to the physical dimension, probably for the longest time, and we didn't even notice it. Let's have a look at say transforms.hpp in dogen.orchestration/types/transforms/:
...
#ifndef DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#define DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#if defined(_MSC_VER) && (_MSC_VER >= 1200)
#pragma once
#endif
/**
* @brief Top-level transforms for Dogen. These are
* the entry points to all transformations.
*/
namespace dogen::orchestration {
...As you can see, whilst the file is located in the right directory, and the header guard also makes the correct reference to the transforms namespace, the documentation is placed against dogen::orchestration rather than dogen::orchestration::transforms, as we intended. Since thus far this was mainly used for documentation purposes, the bug remained unnoticed. This sprint however saw the generation of containers for the physical meta-model (e..g backend and facet), meaning that the bug now resulted in very obvious compilation errors. We had to do some major surgery into how containers are processed in the logical model, but in the end, we got the desired result:
...
#ifndef DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#define DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#if defined(_MSC_VER) && (_MSC_VER >= 1200)
#pragma once
#endif
/**
* @brief Top-level transforms for Dogen. These are
* the entry points to all transformations.
*/
namespace dogen::orchestration::transforms {
...It may appear to be a lot of pain for only a few characters worth of a change, but there is nonetheless something quite satisfying to the OCD amongst us.
Update stitch mode for emacs
Many moons ago we used to have a fairly usable emacs mode for stitch templates based on poly-mode. However, poly-mode moved on, as did emacs, but our stitch mode stayed still, so the code bit-rotted a fair bit and eventually stopped working altogether. With this sprint we took the time to update the code to comply with the latest poly-mode API. As it turns out, the changes were minimal so we probably should have done it before instead of struggling on with plain text template editing.

Figure 2: Emacs with the refurbished stitch mode.
We did run into one or two minor difficulties when creating the mode - narrated on #268: Creation of a poly-mode for a T4-like language, but overall it was really not too bad. In fact, the experience was so pleasant that we are now considering writing a quick mode for wale templates as well.
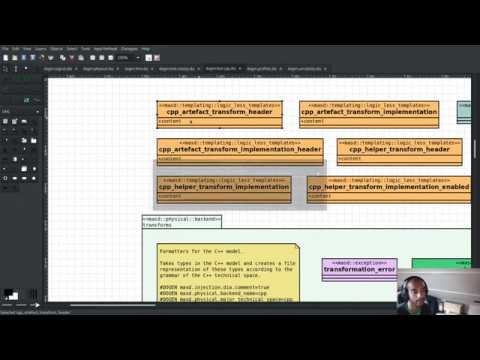
Create archetypes for all physical elements
As with many stories this sprint, this one is hard to pin down as "user facing" or "internal". We decided to go for user facing, given that users can make use of this functionality, though at present it does not make huge sense to do so. The long and short of it is that all formatters have now been updated to use the shiny new logical model elements that model the physical meta-model entities. This includes archetypes and facets. Figure 3 shows the current state of the text.cpp model.

Figure 3: M2T transforms in text.cpp model.
This means that, in theory, users could create their own backends by declaring instances of these meta-model elements - hence why it's deemed to be "user facing". In practice, we are still some ways until that'll work out of the box, and it will remain that way whilst we're bogged down in the never ending "generation refactor". Nevertheless, this change was certainly a key step on the long road to towards achieving our ultimate aims. For instance, it's now possible to create a new M2T transform by just adding a new model element with the right annotations and the generated code will take care of almost all the necessary hooks into the generation framework. The almost is due to running out of time, but hopefully these shortcomings will be addressed early next sprint.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
This sprint had the highest commit count of all Dogen sprints, by some margin; it had 41.6% more commits than the second highest sprint (Table 1).
| Sprint | Name | Timestamp | Number of commits |
|---|---|---|---|
| v1.0.25 | "Foz do Cunene" | 2020-05-31 21:48:14 | 449 |
| v1.0.21 | "Nossa Senhora do Rosário" | 2020-02-16 23:38:34 | 317 |
| v1.0.11 | "Moçamedes" | 2019-02-26 15:39:23 | 311 |
| v1.0.22 | "Cine Teatro Namibe" | 2020-03-16 08:47:10 | 307 |
| v1.0.16 | "São Pedro" | 2019-05-05 21:11:28 | 282 |
| v1.0.24 | "Imbondeiro no Iona" | 2020-05-03 19:20:17 | 276 |
Table 1: Top 6 sprints by commit count.
Interestingly, it was not particularly impressive from a diff stat perspective, when compared to some other mammoth sprints of the past:
v1.0.06..v1.0.07: 9646 files changed, 598792 insertions(+), 624000 deletions(-)
v1.0.09..v1.0.10: 7026 files changed, 418481 insertions(+), 448958 deletions(-)
v1.0.16..v1.0.17: 6682 files changed, 525036 insertions(+), 468646 deletions(-)
...
v1.0.24..v1.0.25: 701 files changed, 62257 insertions(+), 34251 deletions(-)
This is easily explained by the fact that we did a lot of changes to the same fixed number of files (the M2T transforms).
Milestones
No milestones where reached this sprint.
Significant Internal Stories
This sprint had a healthy story count (32), and a fairly decent distribution of effort. Still, two stories dominated the picture, and were the cause for most other stories, so we'll focus on those and refer to the smaller ones in their context.
Promote all formatters to archetypes
At 21.6% of the ask, promoting all formatters to M2T transforms was the key story this sprint. Impressive though it might be, this bulgy number does not paint even half of the picture, because, as we shall see, the implementation of this one story splintered into a never-ending number of smaller stories. But lets start at the beginning. To recap, the overall objective has been to make what we have called thus far "formatters" first class citizens in the modeling world; to make them look like regular transforms. More specifically, like Model-to-Text transforms, given that is precisely what they had been doing: to take model elements and convert them into a textual representation. So far so good.
Then, the troubles begin:
- as we've already mentioned at every opportunity, we have a lot of formatters; we intentionally kept the count down - i.e. we are not adding any new formatters until the architecture stabilises - but of course the ones we have are the "minimum viable number" needed in order for Dogen to generate itself (not quite, but close). And 80 is no small number.
- the formatters use stitch templates, which makes changing them a lot more complicated than changing code - remember that the formatter is a generator, and the stitch template is the generator for the generator. Its very easy to lose track of where we are in these many abstraction layers, and make a change in the wrong place.
- the stitch templates are now modeling elements, carried within Dia's XML. This means we need to unpack them from the model, edit them, and pack them back in the model. Clearly, we have reached the limitations of Dia, and of course, we have a good solution for this in the works, but for now it is what it is; not quick.
- unhelpfully, formatters tend to come in all shapes and sizes, and whilst there is commonality, there are also a lot of differences. Much of the work was finding real commonalities, abstracting them (perhaps into profiles) and regenerating.
In effect, this task was one gigantic, never ending rinse-and-repeat. We could not make too many changes in one go, lest we broke the world and then spent ages trying to figure out where, so we had to do a number of very small passes over the total formatter count until we reached the end result. Incidentally, that is why the commit count is so high.
As if all of this was not enough, matters were made even more challenging because, every so often, we'd try to do something "simple" - only to bump into some key limitation in the Dogen architecture. We then had to solve the limitation and resume work. This was the case for the following stories:
- Profiles do not support collection types: we started to simplify archetypes and then discovered this limitation. Story covered in detail in the user-facing stories section above.
- Extend tracing to M2T transforms: well, since M2T transforms are transforms, they should also trace. This took us on yet another lovely detour. Story covered in detail in the user-facing stories section above.
- Add "scoped tracing" via regexes: Suddenly tracing was taking far too long - the hundreds of new trace files could possibly have something to do with it, perhaps. So to make it responsive again, we added filtering. Story covered in detail in the user-facing stories section above.
- Analysis on templating and logical model: In the past we thought it would be really clever to expand wale templates from within stitch templates. It was not, as it turns out; we just coupled the two rather independent templating systems for no good reason. In addition, this made stitch much more complicated than it needs to be. In reality, what we really want is a simple interface where we can supply a set of KVPs plus a template as a string and obtain the result of the template instantiation. The analysis work pointed out a way out of this mess.
- Split wale out of stitch templates: After the analysis came the action. With this story we decoupled stitch from wale, and started the clean up. However, since we are still making use of stitch outside of the physical meta-model elements, we could not complete the tidy-up. It must wait until we remove the formatter helpers.
templatingshould not depend onphysical: A second story that fell out of the templating analysis; we had a few dependencies between the physical and templating models, purely because we wanted templates to generate artefacts. With this story we removed this dependency and took one more step towards making the templating subsystem independent of files and other models.- Move decoration transform into logical model: In the previous sprint we successfully moved the stitch and wale template expansions to the logical model workflow. However, the work was not complete because we were missing the decoration elements for the template. With this sprint, we relocated decoration handling into the logical model and completed the template expansion work.
- Resolve references to wale templates in logical model: Now that we can have an archetype pointing to a logical element representing a wale template, we need to also make sure the element is really there. Since we already had a resolver to do just that, we extended it to cater for these new meta-model elements.
- Update stitch mode for emacs: We had to edit a lot of stitch templates in order to reshape formatters, and it was very annoying to have to do that in plain text. A nice mode to show which parts of the file are template and which parts are real code made our life much easier. Story covered in detail in the user-facing stories section above.
- Ensure stitch templates result in valid JSON: converting some stitch templates into JSON was resulting in invalid JSON due to incorrect escaping. We had to quickly get our hands dirty in the JSON injector to ensure the escaping was done correctly.
All and all, this story was directly or indirectly responsible for the majority of the work this sprint, so as you can imagine, we were ecstatic to see the back of it.
Create a PMM chain in physical model
Alas, our troubles were not exactly at an end. The main reason why we were on the hole of the previous story was because we have been trying to create a representation of the physical-meta model (PMM); this is the overarching "arch" of the story, if you pardon me the pun. And once we managed to get those pesky M2T transforms out of the way, we then had to contend ourselves with this little crazy critter. Where the previous story was challenging mainly due to its boredom, this story provided challenges for a whole different reason: to generate an instance of a meta-model by code-generating it as you are changing the generator's generator is not exactly the easiest of things to follow.
The gist of what we were trying to achieve is very easy to explain, of course; since Dogen knows at compile time the geometry of physical space, and since that geometry is a function of the logical elements that represent the physical meta-model entities, it should therefore be possible to ask Dogen to create an instance of this model via code-generation. This is greatly advantageous, clearly, because it means you can simply add a new modeling element of a physical meta-type (say an archetype or a facet), rebuild Dogen and - lo-and-behold - the code generator is now ready to start generating instances of this meta-type.
As always, there was a wide gulf between theory and practice, and we spent the back end of the sprint desperately swimming across it. As with the previous story, we ended up having to address a number of other problems in order to get on with the task at hand. These were:
- Create a bootstrapping chain for context: Now that the physical meta-model is a real model, we need to generate it via transform chains rather than quick hacks as we had done in the past. Sadly, all the code around context generation was designed for the context to be created prior to the real transformations taking place. You must bear in mind that the physical meta-model is part of the transform context presented to almost all transforms as they execute; however, since the physical meta-model is also a model, we now have a "bootstrapping" stage that builds the first model which is needed for all other models to be created. With this change we cleaned up all the code around this bootstrapping phase, making it compliant with MDE.
- Handling of container names is incorrect: As soon as we started generating backends and facets we couldn't help but notice that they were placed in the wrong namespace, and so were all containers. A fix had to be done before we could proceed. Story covered in detail in the user-facing stories section above.
- Facet and backend files are in the wrong folder: a story related to the previous one; not only where the namespaces wrong but the files were also incorrect too. Fixing the previous problem addressed both issues.
- Add template related attributes to physical elements: We first thought it would be a great idea to carry the stitch and wale templates all the way into the physical meta-model representation; we were half-way through the implementation when we realised that this story made no sense at all. This is because the stitch templates are only present when we are generating models for the archetypes (e.g.
text.cppandtext.csharp). On all other cases, we will have the physical meta-model (it is baked in into the binary, after all) but no way of obtaining the text of the templates. This was a classical case of trying to have too much symmetry. The story was then aborted. - Fix
static_archetypemethod in archetypes: A number of fixes was done into the "static/virtual" pattern we use to return physical meta-model elements. This was mainly a tidy-up to ensure we useconstby reference consistently, instead of making spurious copies.
MDE Paper of the Week (PofW)
This sprint we spent around 5.2% of the total ask reading four MDE papers. As usual, we published a video on youtube with the review of each paper. The following papers were read:
- MDE PotW 05: An EMF like UML generator for C++: Jäger, Sven, et al. "An EMF-like UML generator for C++." 2016 4th International Conference on Model-Driven Engineering and Software Development (MODELSWARD). IEEE, 2016. PDF.
- MDE PotW 06: An Abstraction for Reusable MDD Components: Kulkarni, Vinay, and Sreedhar Reddy. "An abstraction for reusable MDD components: model-based generation of model-based code generators." Proceedings of the 7th international conference on Generative programming and component engineering. 2008. PDF.
- MDE PotW 07: Architecture Centric Model Driven Web Engineering: Escott, Eban, et al. "Architecture-centric model-driven web engineering." 2011 18th Asia-Pacific Software Engineering Conference. IEEE, 2011. PDF
- MDE PotW 08: A UML Profile for Feature Diagrams: Possompès, Thibaut, et al. "A UML Profile for Feature Diagrams: Initiating a Model Driven Engineering Approach for Software Product Lines." Journée Lignes de Produits. 2010. PDF.
All the papers provided interesting insights, and we need to transform these into actionable stories. The full set of reviews that we've done so far can be accessed via the playlist MASD - MDE Paper of the Week.
Video 2: MDE PotW 05: An EMF like UML generator for C++.
Resourcing
As we've already mentioned, this sprint was particularly remarkable due to its high number of commits. Overall, we appear to be experiencing an upward trend on this department, as Figure 4 attests. Make of that what you will, of course, since more commits do not equal more work; perhaps we are getting better at committing early and committing often, as one should. More significantly, it was good to see the work spread out over a large number of stories rather than the bulkier ones we'd experienced for the last couple of sprints; and the stories that were indeed bulky - at 21.6% and 12% (described above) - were also coherent, rather than a hodgepodge of disparate tasks gather together under the same heading due to tiredness.

Figure 4: Commit counts from sprints 13 to 25.
We saw 79.9% of the total ask allocated to core work, which is always pleasing. Of the remaining 20%, just over 5% was allocated to MDE papers, and 13% went to process. The bulk of process was, again, release notes. At 7.3%, it seems we are still spending too much time on writing the release notes, but we don't seem to find a way to reduce this cost. It may be that its natural limit is around 6-7%; any less and perhaps we will start to lose the depth of coverage we're getting at present. Besides, we find it to be an important part of the agile process, because we have no other way to perform post-mortem analysis of sprints; and it is a much more rigorous form of self-inspection. Maybe we just need to pay its dues and move on.
The remaining non-core activities were as usual related to nursing nightly builds, a pleasant 0.9% of the ask, and also a 1% spent dealing with the fall out of a borked dist-upgrade on our main development box. On the plus side, after that was sorted, we managed to move to the development version of clang (v11), meaning clangd is even more responsive than usual.
All and all, it was a very good sprint from the resourcing front.

Figure 5: Cost of stories for sprint 25.
Roadmap
Other than being moved forward by a month, our "oracular" road map suffered only one significant alteration from the previous sprint: we doubled the sprint sizes to close to a month, which seems wise given we have settled on that cadence for a few sprints now. According to the oracle, we have at least one more sprint to finish the generation refactor - though, if the current sprint is anything to go by, that may be a wildly optimistic assessment.
As you were, it seems.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.25_amd64-applications.deb | dogen_1.0.25_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.25-Darwin-x86_64.dmg | DOGEN-1.0.25-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.25-Windows-AMD64.msi | DOGEN-1.0.25-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The sprint goals for the next sprint are as follows:
- finish PMM generation.
- implement locator and dependencies via PMM.
- move physical elements and transforms from logical and text models
to physical model.
That's all for this release. Happy Modeling!