http://isochrones.envadrouille.org - Don't forget to zoom to show the bus stops! You can also deactivate animations if they are a bit too choppy.
The demo only shows travel times for France, Switzerland and Germany.
Request -- I could not find the GTFS data for Italy (Trenitalia & Italo). Please open an issue if you know how to get them.
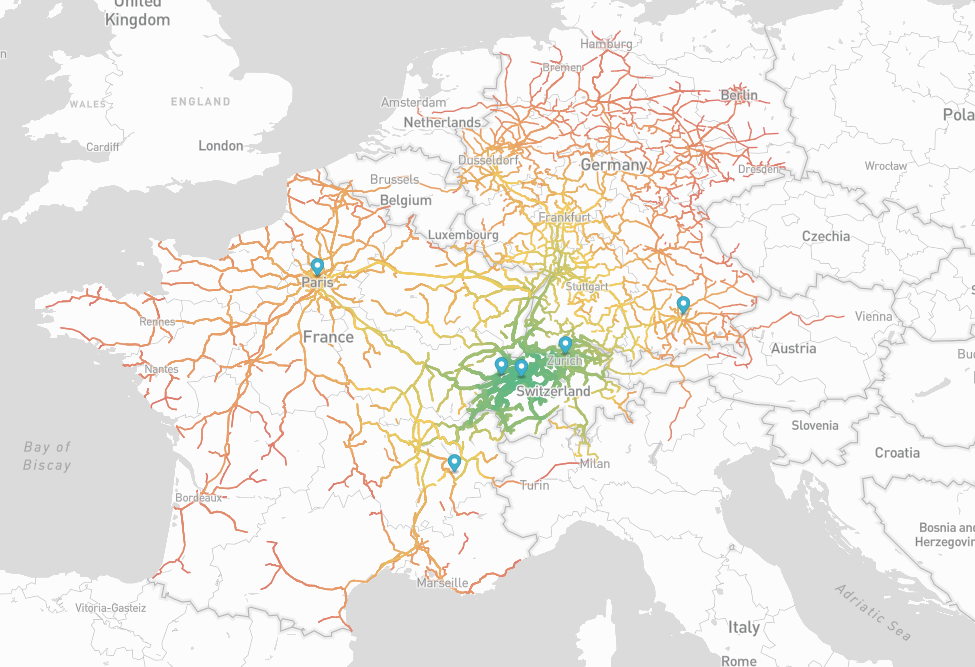
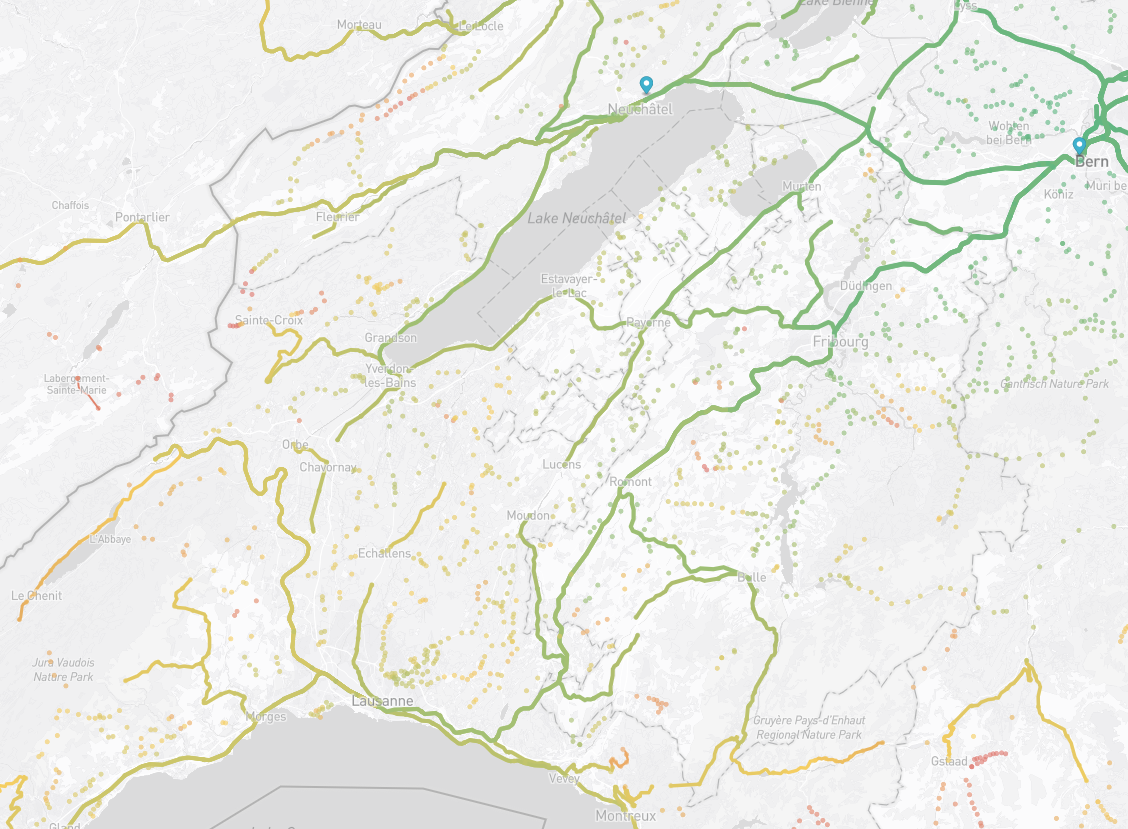
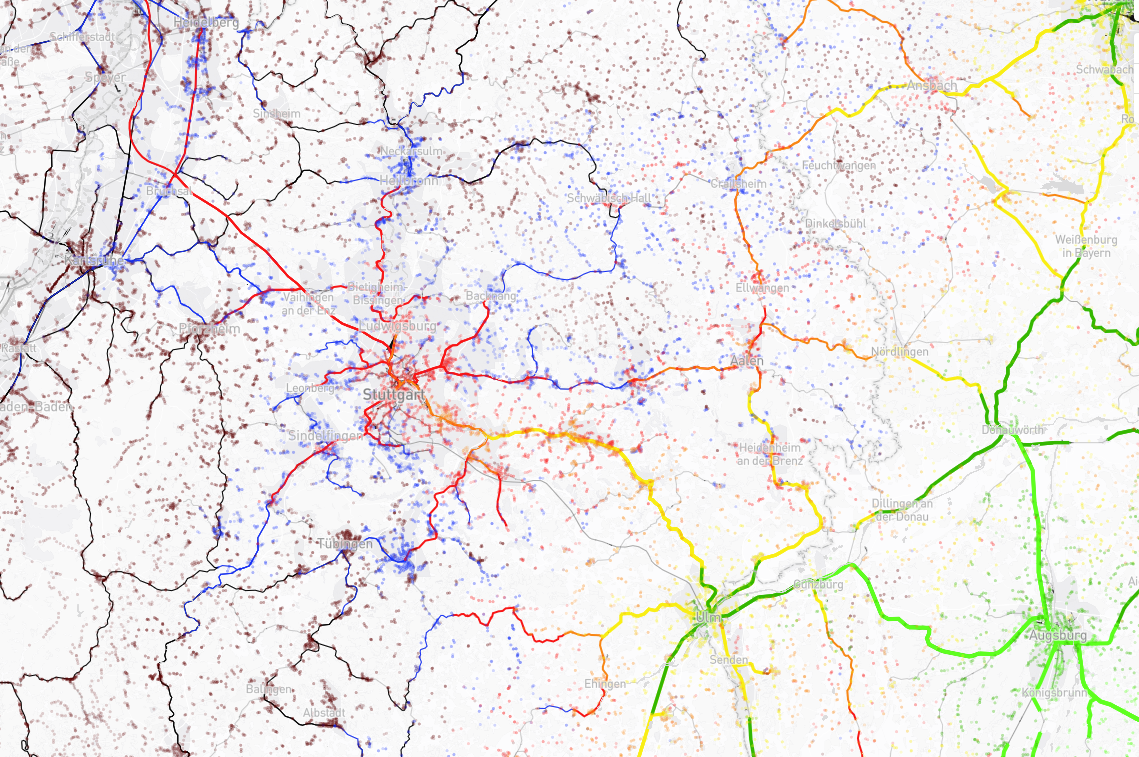
You can contribute by adding more isochrones to the map. Here is how to generate them. The process is quite simple once you have all the datasets, but the setup is a bit long unfortunately...
To generate the shortest times you need ~10GB of free space. To generate the map, you need ~30GB of free space (so 40GB in total).
If you want to generate the shortest pathes for a specific country you need 3-4GB of DRAM. If you want to generate the shortest pathes for the whole of Europe, it's more in the range of 10-15GB.
The GFTS datasets can be found here:
-
Switzerland: https://opentransportdata.swiss/en/dataset/timetable-2023-gtfs2020 (for 2023, change the url for future years)
-
Germany - https://gtfs.de/en/
-
France - No unified dataset.
- TER: https://eu.ftp.opendatasoft.com/sncf/gtfs/export-ter-gtfs-last.zip
- Intercités: https://eu.ftp.opendatasoft.com/sncf/gtfs/export-intercites-gtfs-last.zip
- TGV: https://eu.ftp.opendatasoft.com/sncf/gtfs/export_gtfs_voyages.zip (not sure if this includes OUIGO trains)
- Buses https://github.com/MobilityData/mobility-database-catalogs/tree/main/catalogs/sources/gtfs/schedule for a list of the GTFS files provided by multiple operators
To merge the french train datasets in a single dataset
mkdir ter
wget https://eu.ftp.opendatasoft.com/sncf/gtfs/export-ter-gtfs-last.zip
unzip export-ter-gtfs-last.zip
mv *txt ter
mkdir inter
wget https://eu.ftp.opendatasoft.com/sncf/gtfs/export-intercites-gtfs-last.zip
unzip export-intercites-gtfs-last.zip
mv *txt inter
mkdir tgv
wget https://eu.ftp.opendatasoft.com/sncf/gtfs/export_gtfs_voyages.zip
unzip export_gtfs_voyages.zip
mv *txt tgv
make
mkdir france
./merge ter inter tgv france/For the buses its a bit more complex, I would not recomment doing it when testing the tools because the datasets contain MANY errors. The merge tool will refuse to import quite a few of them. When the tool complains about a missing column or something similar, just remove the specific problematic dataset.
export MAIN_REPO=`pwd`
git clone https://github.com/MobilityData/mobility-database-catalogs
cd mobility-database-catalogs/catalogs/sources/gtfs/schedule/
${MAIN_REPO}/get.pl fr-*json
mkdir francebus
${MAIN_REPO}/merge out* francebus/Note that the script downloads the latest dataset backed up by MobilityData, which may not be the freshest one.
Assuming the directories france, swiss and germany contain unzipped GTFS datasets:
make
mkdir europe
./merge france/ germany/ swiss/ europe/./parse ${gtfs_dir} "${city}" "${date}" 0 > ${city}.jsonE.g.: to generate the isochrones from the Central station of Bern, using the swiss GTFS
./parse swiss/ "Bern, Hauptbahnhof" 20230617 0 > bern.jsonE.g.: to generate the isochrones from the Central station of Bern, using a merged dataset. /!\ The bigger the dataset, the more memory you need and the longer it takes to process. I recommend to test with a the local GTFS dataset (only swiss, or only french trains, etc.) before trying with a global dataset. If any error, it will be faster to debug. /!\
./parse europe/ "Bern, Hauptbahnhof" 20230617 0 > bern.jsonOrigin stop XXX doesn't exist: The station you want to start from does not exist. Make sure that it is present in the stops.txt file. For instance "Bern" does not exist, the name of the central station is "Bern, Hauptbahnhof".
Origin stop XXX is present at very different locations, edit stops.txt: Two stations have the same name in the dataset, so the tool does not know where to start from. For instance "Grenoble" is both the name of the train station of Grenoble, and of a bus stop in Paris... The solution is to edit stops.txt and to change the name of the station you don't want
Service XXX doesn't seem to have any valid date: A train or a bus route is never scheduled. Benign error, the service likely does not run on the chosen date.
Unknown stop XXX: A train or a bus goes to a stop that does not exist in the dataset. Common in the french bus datasets (they contain many errors).
Negative travel time -XXX from XXX at XXX to XXX arrival at XXX previous time was XXX line XXX: A train is indicated as arriving before it departs. The trip will be ignored. Again, common in the French datasets. (E.g.: Negative travel time -3 from CHATEAU D'EAU at 20:07:00 to QUAI DE LA BATELLERIE arrival at 20:04:00(1204) previous time was 1207(20:7) line 40603989)
XXX is before XXX to XXX: Same flavor of error as before.
No path is found from a source to a destination: either the information is not in the dataset, or no train/bus links the source and the destination on the specified date. The parser also cuts the exploration to a maximum of 10 hours. (You can edit parse.cpp to change that.)
The parser also silently ignores all inconsistent trips. The most common inconsistency is trips with unordered stop sequences. For instance a bus goes from stop number 1 to stop number 2 to stop number 5 to stop number 3. Again, common mistake in the french bus datasets.
If you do not understand how the tool managed to go so fast between a source and a destination, just add a
best_path("Name of the stop");... at the end of parse.cpp and recompile. The full path will be printed.
If you see that the tool walked from a stop to another (far away) stop, it is likely due to an error in stops.txt: likely a stop has the wrong (latitude, longitude).
If no path is found, then it is a bit more complicated. The tool has options to print a lot of debug information, but it is tedious to debug. Before going in full debug mode, test another date -- the most common reason that a path does not exist is that construction work happens on the searched date.
Finding the shortest path between train stations is a bit more complex than finding the shortest path driving/cycling/walking because trains depart and arrive at specific times ==> it is not possible to take a train that departs before another one arrives and sometimes one must wait in between trains.
In a nutshell, the program simulates:
- A client takes all the trains from a specific station on a given day.
- The client arrives in some other stations at different times
- From these stations
- The client takes all the trains it can take on the same platform (i.e., the ones that depart after his arrival time)
- The client walks to all the other platforms, and takes all the trains it can take from these platforms
- The client walks to all the nearby bus stops (< 100m) and takes all the buses it can take.
- And so forth.
The parser remembers the arrival times of the client for each station, and how long it took him to reach the station. Unlike traditional shortest path algorithms, we remember the optimal path AND also most of the other pathes that allow reaching the station because sometimes it is faster to take a slow train and then a fast train rather than a fast train followed by a fast train -- for instance if the waiting time between the slow trains is shorter. This happens quite frequently in France...
To avoid combinatory explosion, a client does not walk back and forth from a bus stop to a train station, and the exploration is trimmed in many different way. For instance if the client arrives in a station via a very random path, and this path is 1h longer or more than the current best path, then the client stops exploring further on that path.
The exploration is currently limited to 10 hours of train, you can change the constant in parse.cpp.
Once you are sure that the parse script works and gives you a list of times to all the other stations, you can use script.sh script to automate the creation of the map. READ BELOW BEFORE USING!
- Create a mapbox account.
- In https://account.mapbox.com/ create a token with all "tilesets:XXX" checked in the "Secret scopes". COPY THE GENERATED TOKEN in script.sh.
git clone https://github.com/mapbox/tilesets-cli
cd tilesets-cli
pip install mapbox-tilesetsCheck that the tilesets command exists.
cd osrm-train-profiles
make serveThe make command will take a while: it downloads the whole data for europe (26GB) and then filters it. You may need to install a few dependencies (osmium, etc.). If you don't want to run docker, you will need to compile and install osrm-extract, osrm-partition and osrm-customize from the osrm-backend repository: https://github.com/Project-OSRM/osrm-backend.git, and then modify the Makefile to execute these commands directly:
output/filtered.osrm: output/filtered.osm.pbf basic.lua
osrm-extract -p basic.lua $<
osrm-partition $<
osrm-customize $<
all: output/filtered.osrm
serve: output/filtered.osrm basic.lua
osrm-routed --algorithm mld $<The code of the directory is based on https://github.com/railnova/osrm-train-profile, with a modified basic.lua. Thanks for the code!
Once the above is done, and make serve is running, you can execute script.sh.
- Make sure to set your token
- Make sure to set your usename
- Make sure to set the proper source city and date!
- Make sure to change the tileset name to something unique (e.g., fr-mycity).
Once the tileset is generated and uploaded, make it public: https://studio.mapbox.com/tilesets/, click on the vertical '...' next to your tileset and click make public.
Edit map.html
- Change mapboxgl.accessToken to your PUBLIC token (default public token from https://account.mapbox.com/)
- Add your isochrone in the
isochronesarray.
E.g.:
// If your tileset is "username.tileset", the id MUST BE username-tileset (note the - instead of .)
{ id:"username-tileset", country:"Switzerland", city:"Bern", lat:46.94871, lon:7.43652 },The "username.tileset" value is the one found when making the tileset public (see above).
$ cat tracks.params
nw/highway=tracks
$ cat huts.params
n/tourism=alpine_hut
$ osmium tags-filter --expressions=tracks.params world/switzerland-latest.osm.pbf -o output/switzerland-tracks.pbf
$ ogr2ogr -f GeoJSON output/switzerland-tracks.geojson output/switzerland-tracks.pbf lines # or points for huts
#If the .geojson contains "other_tags", it is better to flatten the structure so that Mapbox can filter the data.
$ cat sanitize.pl
#!/usr/bin/perl
use strict;
use warnings;
use JSON;
use Data::Dumper;
my $data = `cat switzerland-tracks.geojson`;
my $json = decode_json($data);
for my $f (@{$json->{features}}) {
my $p = $f->{properties};
if($p->{other_tags}) { # flatten these tags!
my $s = eval("{".$p->{other_tags}."}");
delete($p->{other_tags});
for my $k (keys %$s) {
$p->{$k} = $s->{$k};
}
}
}
print JSON->new->pretty->encode($json);
$ cat script-tracks.sh
#/bin/bash
export MAPBOX_ACCESS_TOKEN=""
export mapbox_username=""
tileset_id="switzerland"
tileset_recipe="
{
\"version\": 1,
\"layers\": {
\"${tileset_id}-tracks\": {
\"source\": \"mapbox://tileset-source/${mapbox_username}/${tileset_id}-tracks\",
\"minzoom\": 1,
\"maxzoom\": 10
}
}
}
"
echo $tileset_recipe > ${tileset_id}-tracks.recipe
tilesets upload-source --replace ${mapbox_username} ${tileset_id}-tracks output/${tileset_id}-tracks-fixed.geojson
tilesets create ${mapbox_username}.${tileset_id}-tracks --recipe ${tileset_id}-tracks.recipe --name "${tileset_id}-tracks"
tilesets publish ${mapbox_username}.${tileset_id}-tracks
$ bash ./script-tracks.sh
That's it! Feel free to send me new isochrones to add on the demo map!