Design
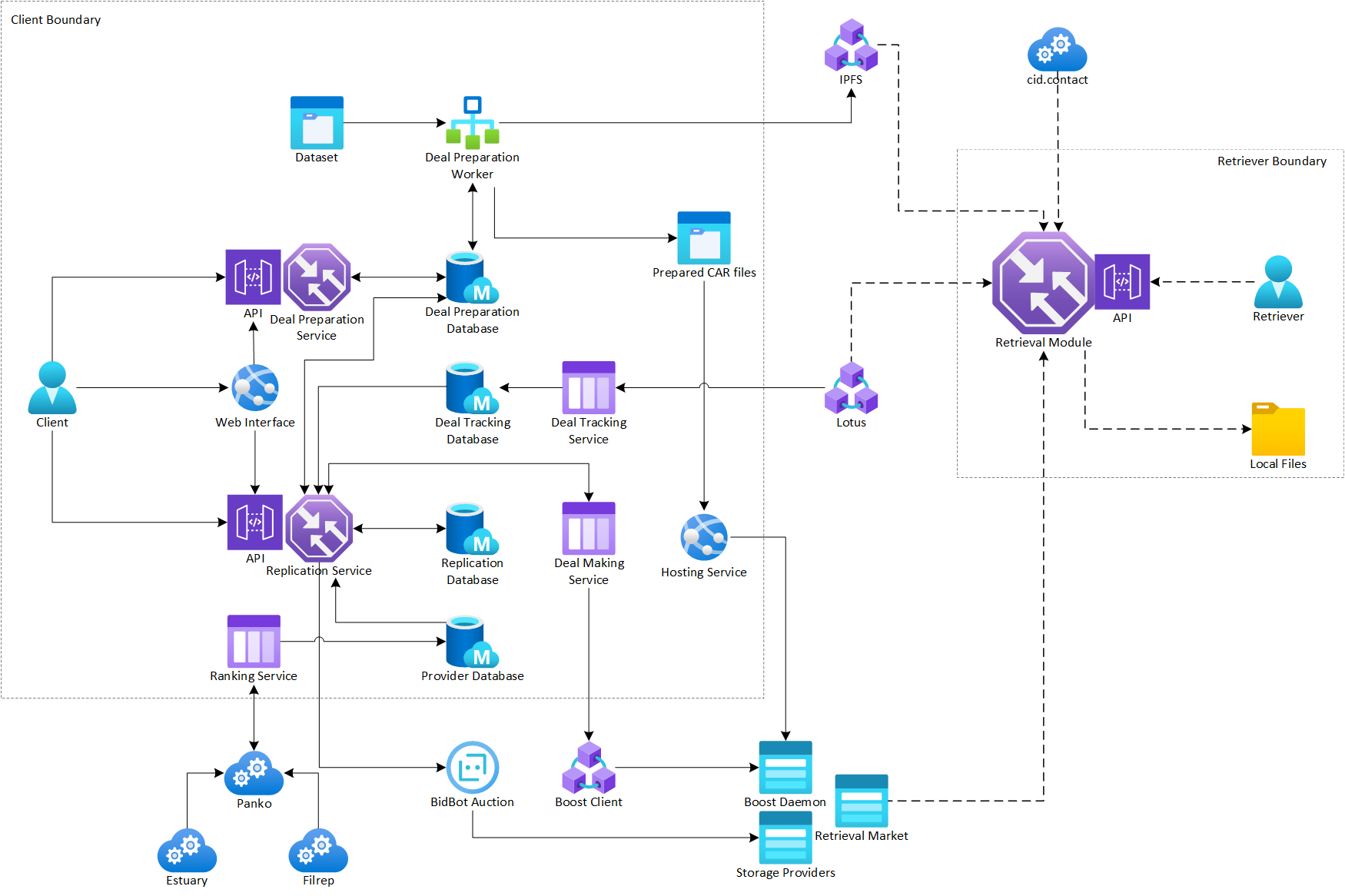
Have a modularized and simple software solution to allow clients to store and end users to retrieve files via Filecoin storage provider network.
| Component | Responsibility | External Dependencies |
|---|---|---|
| Deal Preparation Service | Accept request from client to prepare dataset. | - |
| Deal Preparation Worker | Scan dataset folder, split dataset into chunks, prepare CAR files and calculate commp. | - |
| Deal Making Service | Wrap around Boost Client CLI that can be used to send out stateless deals | Boost Client CLI and its dependencies |
| Deal Tracking Service | Update the deal state by looking at on-chain messages | lotus for chain head notification |
| Replication Service | Replicate prepared dataset to Filecoin storage providers | - |
| Ranking Service | Subscribe to provider metrics published by estuary/filrep via pando | Pando integration with Estuary/Filrep |
| Http Hosting Service | Host the generated car files | - |
With the default configuration, all services/modules will be run on a single host and uses the same database. However, all of above components can be run on different host as long as they are connecting to the database that contains the collections they need.
The software can also be utilized in a creative way to offer part of the feature to users. Below table summarizes how end user scenarios maps to what components to enable if the user does not want to enable all contained modules.
| Scenario | Components to enable | Details |
|---|---|---|
| As a client, I just need to prepare some CAR files from a dataset | Deal Preparation Service, Deal Preparation Worker | CAR files will be generated. dataCid, pieceCid and ipld dag structure will be saved in the database |
| As a client, I have some CAR files on hand and just need to replicate them with selected storage providers | Deal Making Service, Deal Tracking Service, Replication Service | Client can also use Ranking Service to filter and select the storage providers. pieceCid and dataCid will be generated if the client does not provide them |
All databases used by above services will be MongoDB service. By default, A local MongoDb service will be shipped with the software and automatically starts up. More experienced users can setup their own database and provide a connection string in the config.
Use below configuration to start the database with the service
[database]
enabled = true
path = "./.singularity/database"
bind = "127.0.0.1"
port = 37000The entry point of the whole service that handles user requests to prepare deal. Talks to a MongoDB database to manage the state of each request.
[connection]
database = "mongodb://127.0.0.1:37000"
[deal_preparation_service]
enabled = true
bind = "127.0.0.1"
port = 3001
ipfs_api = "http://127.0.0.1:5001"The service will perform simple validation of the request and store the request in the database table. The preparation request is fulfilled with two steps by the Deal Preparation Workers
- Scanning - scan the dataset to understand the folder structure and split them into chunks
- Generation - for each chunk of the dataset, generate CAR files and compute commp
- Indexing - generate the index dag and pin to IPFS network
Whenever the service received a preparation request, it will insert an entry in the database collection ScanningRequest so a worker can poll for this task later.
{
id: string, // auto generated
name: string // dataset name, provided by the client
path: string, // path of the dataset, provided by the client
minSize: string, // min size of the CAR archive, default to 0.6 * deal size
maxSize: string, // max size of the CAR archive, default to 0.9 * deal size
workerId: string, // worker assigned to this task
status: string // active, paused, removed, completed
indexCid: string
}Request
POST /preparation
{
"name": "dataset_name",
"path": "/mnt/dataset/path",
"dealSize": "32 GiB", --> must be power of 2.
"minSize": "20 GiB", --> optional
"maxSize": "30 GiB" --> optional
}
Response
{
"id": "xxxxx"
}Once a preparation request is created, it can be paused, resumed and removed.
- Paused means all dataset preparation and generation should no longer happening however can be resumed later
- Removed means removing the entry in the database
POST /preparation/:id
{
"state": "paused|active|removed"
}
Request
GET /preparations
Response
[
{
"id": "id",
"name": "dataset_name",
"path": "path",
"dealSize": "32 GiB",
"minSize": "20 GiB",
"maxSize": "30 GiB",
"scanningStatus": "active",
"generationCompleted": 10,
"generationInprogress": 2,
"generationTotal": 50
}
]Request
GET /preparation/:id
Response
{
"id": "id",
"name": "dataset_name",
"path": "path",
"dealSize": "32 GiB",
"minSize": "20 GiB",
"maxSize": "30 GiB",
"scanningStatus": "active",
"generationCompleted": 10,
"generationInprogress": 2,
"generationTotal": 50,
"generationRequests": [
{
"id": "id",
"index": 0,
"workerId": "xxx",
"status": "active",
"dataCid": "bafy",
"pieceCid": "bafy",
"pieceSize": 1024
}
...
]
}Request
GET /generation/:id
Response
{
"id": "id",
"name": "name",
"path": "path",
"index": 0,
"fileList": [
{
"path": "/path/to/file1.mp4",
"name": "file1.mp4",
"size": 4096,
"start": 0,
"end": 2048
},
...
],
"workerId": "xxx",
"state": "active",
"dataCid": "bafy",
"pieceCid": "bafy",
"pieceSize": 1024
}The service will perioidcally check the database for any expired workerIds, all requests assigned to expired workers will have the workerId cleared so another worker can pick up the task.
Poll for work to scan the dataset and generate car files.
[connection]
database = "mongodb://127.0.0.1:37000"
[deal_preparation_worker]
enabled = true
parallelism = 2
out_dir = "./.singularity/cars"The worker will periodically report health to the database. If the worker failed to report health for certain period, the entry should be removed by orchestrator service
{
workerId: string, // uuid generated during worker startup
updatedAt: Date
}The worker will periodically look for ScanningRequest that
- has not been completed
- does not have assigned worker
To scan the dataset
- perform a Glob pattern match and get all files in sorted order
- iterate through all the files and keep accumulating file sizes into a chunk
- Once the size of the chunk is between
minSizeandmaxSize, start with a new chunk - If the size of a file is to large to put into a chunk, split the file to hit the chunk
minSize
Caveat: Due to IPFS chunking, the resulting CAR files may be smaller than expected if there are duplicate chunks, i.e. duplicate file or file content.
Once scanned, all chunks have their own list of file paths. Save the filelist within each chunk to database GenerationRequest table so another worker will pick up the generation request later.
{
id: string, // auto generated
name: string, // dataset name
path: string, // dataset path
index: number, // the index of the chunk for that dataset
fileList: { // list of files to include in this chunk
path: string,
name: string,
size: number,
start: number,
end: number // both start and end being non zero indicates partial file
}[],
workerId: string, // assigned worker
status: string, // active, paused, removed, completed
dataCid: string, // root cid of ipld
pieceCid: string, // commp
pieceSize: number // deal size
}The worker will periodically look for GenerationRequest that
- has not been completed
- does not have assigned worker
To generate car files and calculate commp
- Build IPLD DAG representing the unixfs structure of the file list. Reference code
- Calculate CommP using code from stream-commp
- To save some disk IO, the above two can be accomplished in one go with streaming
- Save the dataCid, pieceCid, pieceSize to database
- The CAR files will be generated under
out_dirwith filename<cid>.car. Those files will be picked up by the HTTP hosting server
Store the index and metadata in IPFS.
The goal of the index is to allow end user to visit individual files or folders with similar experience of visiting files from local file system. The design needs to address a few things
- If the folder or the file is splitted across different deals, they need to be reassembled back
- The user should be able to search for files they want by filename and path
- Avoid dependency on a centralized or a single service endpoint
To achieve above goals, we want to leverage IPFS as a storage to store the metadata for the file structures and IPNS to provide a fixed path to look for such metadata. The metadata will be structured simiarly to Unixfs, but with DAG-CBOR codec.
DataModel {
__type: DataType,
__size: Number,
__source: SourceInfo[],
// And other subfiles
}
SourceInfo {
cid: string,
selector: string,
offset: Number,
length: Number
}When all CAR files are generated from the original dataset, the software will assemble the DAG and pin the object to IPFS network. The client can then utlize DNSLink to publish the object to their DNS records.
Once published, the metadata can be queryable with a human friendly IPFS path or URL via IPFS Gateway.
Once the dataset has been prepared, the client can retrieve the IPFS path for the metadata object.
singularity preparation status
This will return an IPFS link, i.e. /ipfs/bafyxxx
The retrieval follows below steps
- The user supplys the domain and the path to the folder or file to retrieve, i.e.
singularity retrieve my.dataset.com/path/to/file.mp4 - The software looks up the ipfs dag object under
/ipns/my.dataset.com/path/to/file.mp4, the data contains the type of the object as well as a list ofSourceInfo - If the sourceInfo contains a single entry, then the item was not splitted and can be retrieved using the dataCid and the data model selector
- If the sourceInfo contains multiple entries, then the item has been splitted. Download each entry and reassemble them using the
offset,lengthandfilesizeinformation. - To map the dataCid to the actual storage provider that stores this data, use the
cid.contactbuilt by Protocol Lab.
User space file system mount (FUSE) will be possible as the above data structure provides sufficient data for POSIX readdir, getattr and read.
Send proposals over libp2p with HTTP link for storage provider to download and import.
It may be a simple wrapper around Boost Client CLI. Below API may be subject to change depending on the final implementation of Boost Client CLI. Once a deal is made, a proposalCid will be returned
[deal_making_service]
enabled = true
other_boost_client_cli_options = "such as lotus connection"Note, this is just an example and will depend on the outcome of boost client.
Request
POST /deal
{
"wallet" : "f1xxxxxx",
"keyPath" : "path/to/private/key",
"verified" : true,
"url" : "http://example.com/bafyxxxx.car",
"pieceSize": 256,
"pieceCid": "bafyxxxxx",
"dataCid": "bafyxxxxxx",
"provider": "f01234"
}
Response
{
"proposalCid": "bafyxxxxxx"
}Periodically update the status for each proposal_cid and deal_id
Subscribe lotus daemon chain notification and update deal state according to deal state spec. Updated deal states will be stored in database.
- Unpublished -> Published, triggered by PublishStorageDeals
- Published -> Deleted, if sealing takes too long
- Published -> Active, after successful PreCommit and ProveCommit
- Active -> Deleted, if expired or teminated
- Use filfox API to get deal IDs for a specific client.
- Use Glif nodes to check deal status for those published deals
[connection]
database = "mongodb://127.0.0.1:37000"
full_node_api = "http://127.0.0.1:1234"
full_node_token = "token"
[deal_tracking_service]
enabled = true{
datasetId: string,
client: string,
provider: string,
proposalCid: string,
label: string,
dealId: number,
sectorId: number,
activation: number,
expiration: number,
state: string // proposed, published, active, slashed
}
{
lastHeight: number // to track which height to resume when coming back online
}Entry point for the client to start replicate a prepared dataset to Filecoin storage providers. Ensure each chunk of the dataset is replicated according to client's requirement.
[connection]
database = "mongodb://127.0.0.1:37000"
[replication_service]
enabled = true
bind = "127.0.0.1"
port = 3002
http_url_prefix = "http://example.com" # This will send out deal with URL http://example.com/bafyxxxx.carStands up an API that accept replication request
Request
POST /replication
{
"datasetId": "id",
"minReplicas": 3,
"criteria": "provider in (f0100, f0101, f0102) && success_rate > 0.5",
"client": "client",
}
Request
POST /replication
{
"path": "/mnt/dataset/bafy.car",
"dataCid": "bafy...",
"pieceCid": "bafy...",
"pieceSize": 1024,
"minReplicas": 3,
"criteria": "provider in (f0100, f0101, f0102) && success_rate > 0.5",
"client": "client",
}
Request
POST /replication/:id
{
"minReplicas": 3,
"criteria": "provider in (f0100, f0101, f0102) && success_rate > 0.5",
"client": "client",
"state": "paused|active|removed"
}
Request
GET /replications
Response
[
{
"id": "id",
"datasetId": "id",
"minReplicas": 3,
"client": "client",
"criteria": "provider in (f0100, f0101, f0102) && success_rate > 0.5",
"status": "active",
"replicationFactor": 1.5,
"replicationCompleted": 10,
"replicationInProgress": 2,
"replicationTotal": 50
}
]Request
GET /replication/:id
Response
{
"id": "id",
"datasetId": "id",
"minReplicas": 3,
"client": "client",
"criteria": "provider in (f0100, f0101, f0102) && success_rate > 0.5",
"status": "active",
"replicationFactor": 1.5,
"replicationCompleted": 10,
"replicationInProgress": 2,
"replicationTotal": 50,
"replicationDetails": [
{
"generationRequestId": "id",
"index": 0,
"dataCid": "bafy",
"pieceCid": "bafy",
"pieceSize": 1024,
"deals": [
{
"client" : "client",
"provider": "provider",
"proposalCid": "proposalCid",
"dataCid" : "dataCid",
"dealId": "dealId",
"sectorId": "sectorId",
"activation" : 123123,
"expiration" : 123123,
"state": "published"
}
...
]
...
}
]
}{
id: string,
datasetId: string,
minReplicas: number,
criteria: string,
client: string,
status: string // active, paused, removed, completed
}Periodically look at the replication request table
- For each replication request
- Find corresponding prepared dataset chunks in
GenerationRequesttable. - Look for deals for each Chunk in
DealStatetable, and for those that do not meet minReplica requirement - Find storage providers in
ProviderMetrictables that satisfy the criteria - Send deals to storage providers using Deal Making Service
- Exponential backoff if the storage provider rejects the deal
Forward the replication request to bidbot auctioneer. Currently it is not clear how the API will look like, but it should be some API where we can send the HTTP url along with other options such as minimum copy of replicas and get a jobId in the response. We can later query the API again with the jobId to get the status of the replication request
Periodically get the latest stats of storage providers from Pando and report deal making stats back to Pando.
No longer needed as Filrep will be publishing data to Pando. Only integration with Pando is required
Pando, as a pub-sub service based on libp2p, does not care about the data model of the underlying payload. It's up to the data provider and consumer to agree on a protocol for how to interprete the data transmitted. That means
- As a consumer of data from Estuary or filrep, they need to publish a document detailing how we may consume their published data
- As a provider of data to Pando, we will need to document how our data should be consumed and help consumers to integrate with our data.
- As this software gets distributed to large clients, each client will have their own peer id. Each consumer will need to discover and trust those peer ids. Since any peer can publish data to Pando, there needs to be a way to certify the peer trustworthy. One way to do that is to have an organization serving as authority, who will verify identity for large clients and publish those whitelisted peerIds. Consumer will get the list of peerIds every day and trust the data coming from those peerIds.
Consume data from Pando, and update the corresponding database.
Unknown as we haven't yet seen any published data from Estuary/Filrep via Pando and how to consume them. Below is a tentative structure
{
provider: string
dataProvider: string
metricName: string
metricValue: mixed
}[ranking_service]
enabled = trueRequest
POST /ranking/lookup
{
"limit": 100,
"criteria": [
["filrep.success_rate", "gt" 0.5],
["filrep.available", true],
["id", "in", "f0111", "f0222"]
]
}
Response
[
{
"id": "f0111",
"filrep.success_rate": 0.6
}
]A simple HTTP server that hosts the CAR files
[http_hosting_service]
enabled = true
bind = "0.0.0.0"
port = 80
car_dir = ".singularity/cars/"A light CLI tool that wraps around APIs above
[connection]
deal_preparation_service = "http://127.0.0.1:3001"
replication_service = "http://127.0.0.1:3002"$ singularity preparation|prep start --name <name> --path <path> --deal-size 2GiB
Accepted. dataset-id: 1234
$ singularity preparation pause <dataset_id>
$ singularity preparation resume <dataset_id>
$ singularity preparation remove <dataset_id>
$ singularity preparation list
$ singularity preparation status <dataset_id>
$ singularity replication|rep start --dataset-id <dataset_id> --minReplicas <number> --criteria <criteria>
Accepted. replication request-id: 5678
$ singularity replication update <request_id>
$ singularity replication pause <request_id>
$ singularity replication resume <request_id>
$ singularity replication remove <request_id>
$ singularity replication list
$ singularity replication status <request_id>
$ ssingularity provider lookup --id id1,id2,id3 --criteria <criteria>A CLI tool that connects to libp2p and can be used to download and merge files
[connection]
full_node_api = "https://api.node.glif.io"
full_node_token = ""singularity retrieve my.dataset.com/a/video/file.mp4 --output . [--provider f0xxxx]The deal preparation can be scaled by increasing the number of deal preparation worker. Currently, with AMD SHA extension, it takes about 4 minutes to prepare a 32GiB CAR file. After scaling out, the bottleneck will become the disk speed. Below is the estimate of deal preparation speed depending on the hardware spec
| Storage Type | IO | # of workers | TiB per day |
|---|---|---|---|
| Single SATA HDD | 200 MB/s | 1 | 8 TB |
| Raid 10 with 8 HDD | 800 MB/s | 3 | 36 TB |
| SAN network | up to 20 GB/s | 60 | 800 TB |
Since all deals are made with boost client, each deal making is lightweight and does not need additional node to scale out. The bottleneck will be the data transfer from client's HTTP server to storage provider. The software provides a built-in HTTP server but the client can substitute with any other HTTP server, including hosting the data on S3. Below is the estimate of deals made per day depending on the Internet speed. This estimate is the upper bound and the actual speed may be significantly lower.
| Internet Speed | Deal making per day |
|---|---|
| 1 Gbps | 8 TB |
| 10 Gbps | 80 TB |
| 200 Gbps | 1.6 PB |
We shall start testing while developping the software.
- Test deal preparation with files of different sizes, from 1 byte to 1 TiB.
- Test deal preparation with folders containing different files of different sizes
- Test deal preparation with files of different types, including hidden files
- Test deal preparation with files that does not have read access
- Test deal preparation with files that are changed during preparation
- Test deal preparation with remote mounted file system such as AWS S3
- Verify computed CIDs
- Verify computed Metadata DAG
- Test deal tracking with existing client addresses
- Test deal tracking with deal state changing to published, active, slashed
- Test reputation service with data from Pando
- Test integration with Bidbot
- Test the deal making API to confirm deal being made to corresponding storage providers
- Test deal making with selected storage providers (SPX or enterprise wg)
- Monitor deal making with deals in different state, including failed and slashed.
- Test retrieval CLI with sealed deals and published index metadata
- Test retrieval of single file, single folder, whole dataset, splitted large file, splitted large folder
In this phase, we will be onboarding a selected dataset (~100TiB) with selected storage providers (SPX or enterprise WG). All components will be involved during this phase of testing to make sure each components are integrated well with each other.
In this phase, we will start deploying the solution to multiple nodes and achieve horizontal scalability. We will also setup different components in a different node to validate the connectivity and configuration. We will also validate modularization of the software as described in Modularize
In this phase, we will deploy solution with bigger scale and will demonstrate onboarding PiB of dataset within 30 days with selected storage providers (SPX or enterprise WG)