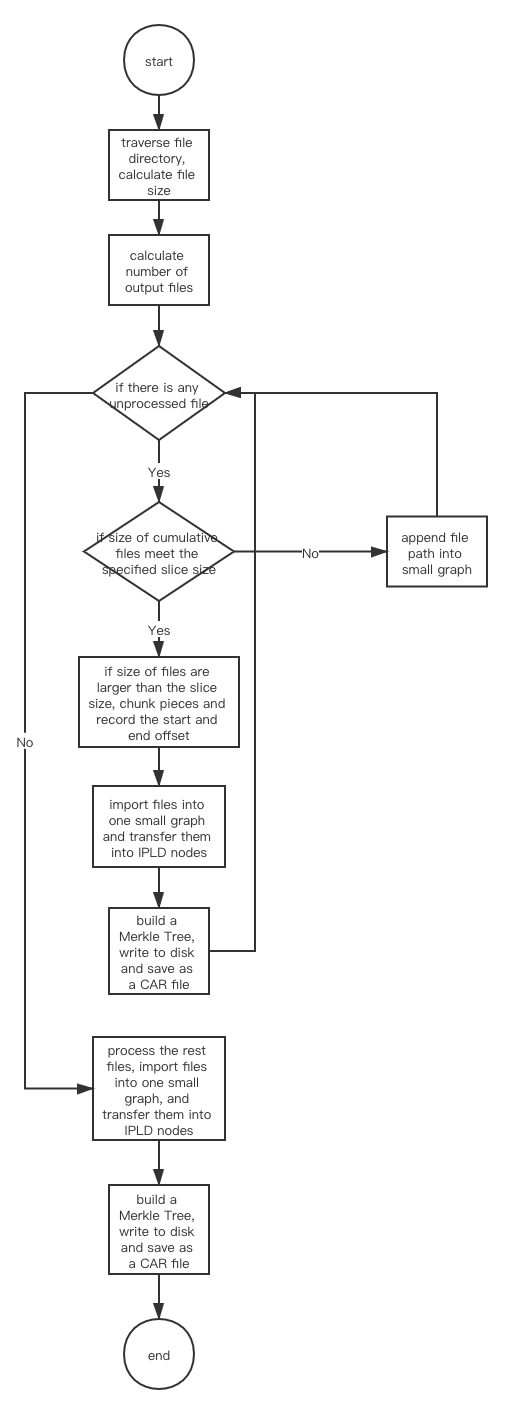
Firstly, traverse the entire directory and calculate the size of the directory. According to the slice size, calculate the number of ouput files.
Then traverse the directory to check whether there is any unprocessed file or not.
- If yes, go on checking whether the size of cumulative files or file slices meet the specified slice size or not.
- If no, append file path into the small graph and repeat the process of traversing the directory to check if there is any unprocessed file.
- If yes, continue checking if the size of files is larger than the specified slice size. If so, chunk pieces, and record the start offset and end offset of the file.
- If no, append the files' path into the small graph, and then traverse the file directory to check if there is any unprocessed files.
At the end, process the rest of the file list, import files from one small graph and transfer them into IPLD nodes. Then build a Merkle Tree with these nodes, write to disk and save as a CAR file.
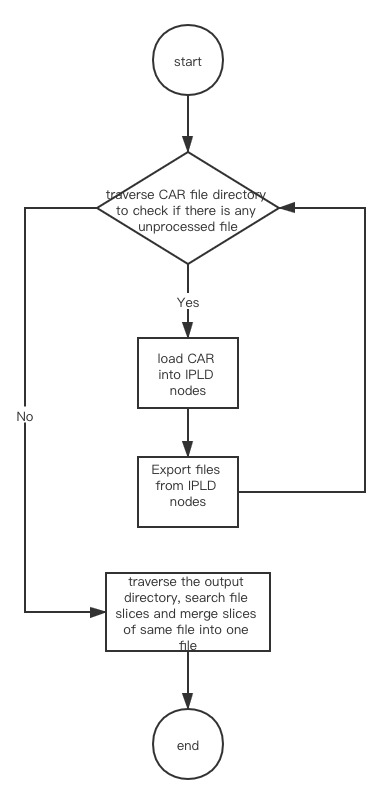
Firstly, traverse the CAR file directory to check if there is any unprocessed file.
- If yes, load CAR files into IPLD nodes. After processing, export files from IPLD nodes. And then traverse the CAR file directory again to check if there is any unprocessed files.
- If no, traverse the output directory directly, search file slices according to special suffix and merge slices of the same file into one file.