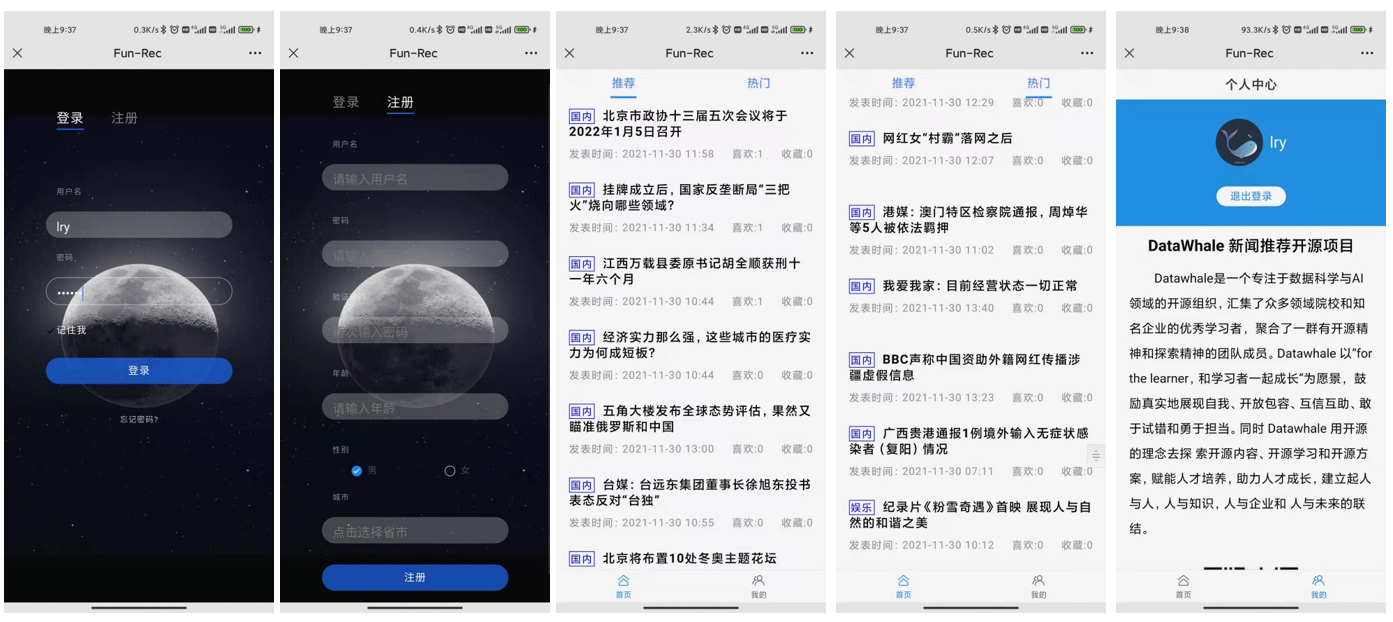
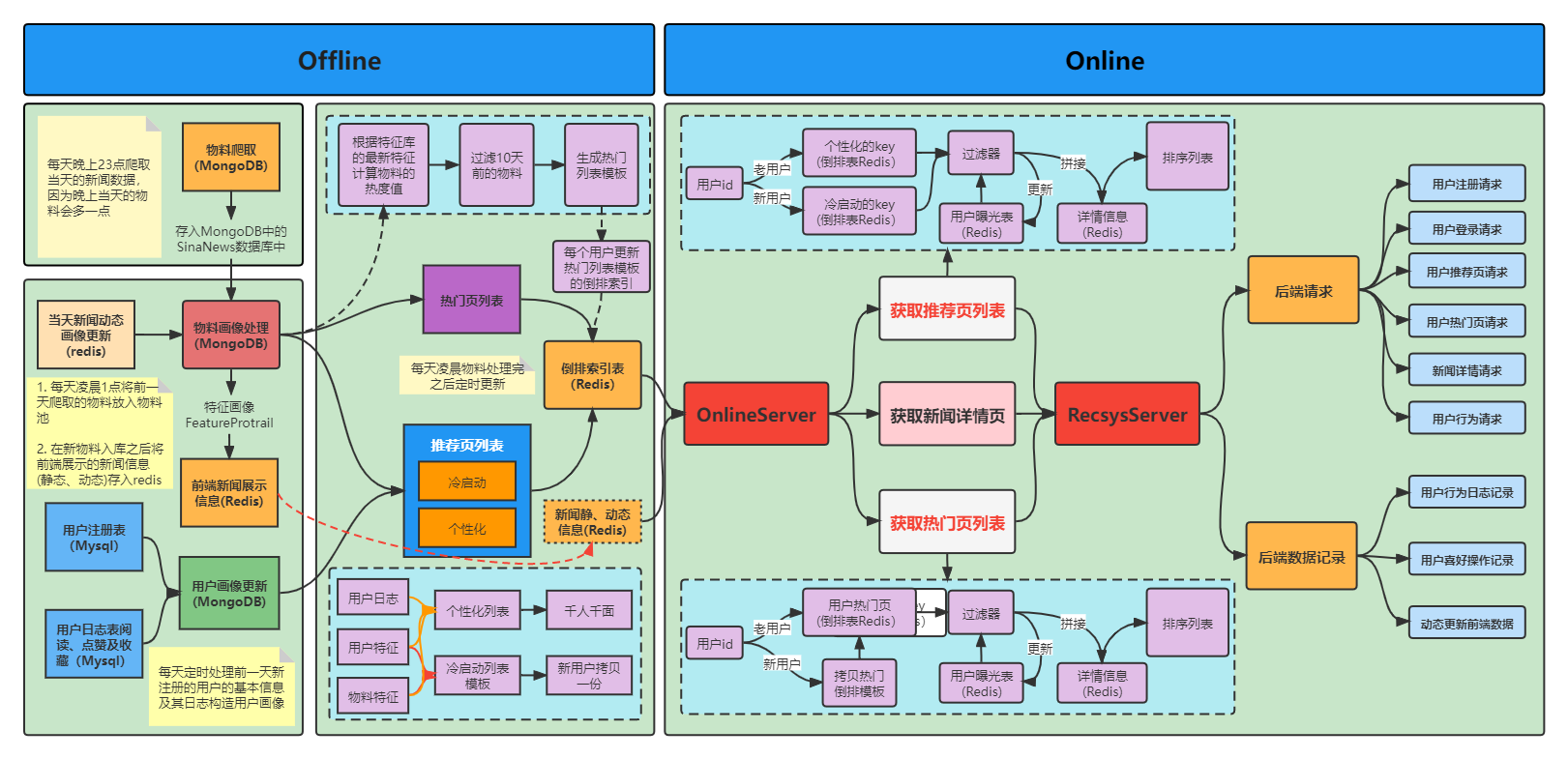
早期的新闻推荐系统实践内容中使用数据库(Mysql/Mongo/Redis)+ 前端(Vue)+ 后端(Flask)实+ 推荐策略,实现了推荐系统的基本流程。下面简单对该系统进行总结,看完之后看大家是能从中获取到相应的内容。
- 系统将新闻的爬取、预处理、入库等事情都串在了一起,并将整个过程都自动化的执行
- 对于展示的新闻内容,没有使用复杂的推荐算法,仅仅是通过简单的策略实现了热门打分,然后按照热度分进行排序。此外,考虑到展示的内容可能同类别的都排在了一起,实现了一个简单的类别打散的策略。(注意:整个系统中都没有排序相关的模型,只有简单的规则类召回)
- 当前系统虽然能够实现用户的注册,点击等交互功能,但是由于使用的用户很少,很难得到一个比较好的用户行为数据,也就无法有效的将该系统迭代起来,甚至都无法很好的对推荐效果进行评估。
- 为了实现能够对系统中的推荐算法进行有效的评估,我们在代码中还想嵌入一个现有的公开新闻推荐数据集,这个数据集是科大讯飞的一个竞赛数据集。所以在代码中的recall和rank目录下添加了一部分处理竞赛数据集的代码,目前由于时间原因,还没有把整个竞赛数据集全部迁入到数据库、前端展示等环节。也就是说基于竞赛数据集的系统和上面提到的(已经完全可以运行的基于规则的新闻推荐系统),是完全脱节的,后面会花时间把整个流程给串起来。这里用到的竞赛相关的数据下载连接(注意:不能作为商业用途):https://cowtransfer.com/s/5461d6c2fdfb4c 或 打开【奶牛快传】cowtransfer.com 使用传输口令:2v5lky 提取;
该新闻推荐系统只是基于现有的技术,实现了推荐系统的基本流程,对于架构是否合理,技术选型是否合理都没有深入研究,这也是未来该项目的优化方向,会结合实际工业的推荐系统对其进行不断的迭代优化。
新闻推荐系统实践前端展示和后端逻辑(项目没有任何商用价值仅供入门者学习)