这是 Airbnb 于2018年发表的一篇论文,主要介绍了 Airbnb 在 Embedding 技术上的应用,并获得了 KDD 2018 的 Best Paper。Airbnb 是全球最大的短租平台,包含了数百万种不同的房源。这篇论文介绍了 Airbnb 如何使用 Embedding 来实现相似房源推荐以及实时个性化搜索。在本文中,Airbnb 在用户和房源的 Embedding 上的生成都是基于谷歌的 Word2Vec 模型,故阅读本文要求大家了解 Word2Vec 模型,特别是 Skip-Gram 模型**(重点*)**。 本文将从以下几个方面来介绍该论文:
- 了解 Airbnb 是如何利用 Word2Vec 技术生成房源和用户的Embedding,并做出了哪些改进。
- 了解 Airbnb 是如何利用 Embedding 解决房源冷启动问题。
- 了解 Airbnb 是如何衡量生成的 Embedding 的有效性。
- 了解 Airbnb 是如何利用用户和房源 Embedding 做召回和搜索排序。
考虑到本文的目的是为了让大家快速了解 Airbnb 在 Embedding 技术上的应用,故不会完全翻译原论文。如需进一步了解,建议阅读原论文或文末的参考链接。原论文链接:https://dl.acm.org/doi/pdf/10.1145/3219819.3219885
在介绍 Airbnb 在 Embedding 技术上的方法前,先了解 Airbnb 的业务背景。
- Airbnb 平台包含数百万种不同的房源,用户可以通过浏览搜索结果页面来寻找想要的房源。Airbnb 技术团队通过复杂的机器学习模型,并使用上百种信号对搜索结果中的房源进行排序。
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
- 返回搜索结果页,继续查看其他搜索结果。

- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
Airbnb 描述了两种 Embedding 的构建方法,分别为:
- 用于描述短期实时性的个性化特征 Embedding:listing Embeddings
- listing 表示房源的意思,它将贯穿全文,请务必了解。
- 用于描述长期的个性化特征 Embedding:user-type & listing type Embeddings
Listing Embeddings 是基于用户的点击 session 学习得到的,用于表示房源的短期实时性特征。给定数据集 $ \mathcal{S} $ ,其中包含了 $ N $ 个用户的 $ S $ 个点击 session(序列)。
- 每个 session $ s=\left(l_{1}, \ldots, l_{M}\right) \in \mathcal{S} $ ,包含了 $ M $ 个被用户点击过的 listing ids 。
- 对于用户连续两次点击,若时间间隔超过了30分钟,则启动新的 session。
在拿到多个用户点击的 session 后,可以基于 Word2Vec 的 Skip-Gram 模型来学习不同 listing 的 Embedding 表示。最大化目标函数 $ \mathcal{L} $ : $$ \mathcal{L}=\sum_{s \in \mathcal{S}} \sum_{l_{i} \in s}\left(\sum_{-m \geq j \leq m, i \neq 0} \log \mathbb{P}\left(l_{i+j} \mid l_{i}\right)\right) $$ 概率 $ \mathbb{P}\left(l_{i+j} \mid l_{i}\right) $ 是基于 soft-max 函数的表达式。表示在一个 session 中,已知中心 listing $ l_i $ 来预测上下文 listing $ l_{i+j} $ 的概率: $$ \mathbb{P}\left(l_{i+j} \mid l_{i}\right)=\frac{\exp \left(\mathbf{v}{l{i}}^{\top} \mathbf{v}{l{i+j}}^{\prime}\right)}{\sum_{l=1}^{|\mathcal{V}|} \exp \left(\mathbf{v}{l{i}}^{\top} \mathbf{v}_{l}^{\prime}\right)} $$
- 其中, $ \mathbf{v}{l{i}} $ 表示 listing $ l_i $ 的 Embedding 向量, $ |\mathcal{V}| $ 表示全部的物料库的数量。
考虑到物料库 $ \mathcal{V} $ 过大,模型中参数更新的时间成本和 $ |\mathcal{V}| $ 成正比。为了降低计算复杂度,要进行负采样。负采样后,优化的目标函数如下: $$ \underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}{p}} \log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime^{\prime}} \mathbf{v}{l}}}+\sum{(l, c) \in \mathcal{D}{n}} \log \frac{1}{1+e^{\mathbf{v}{c}^{\prime} \mathbf{v}_{l}}} $$ 至此,对 Skip-Gram 模型和 NEG 了解的同学肯定很熟悉,上述方法和 Word2Vec 思想基本一致。 下面,将进一步介绍 Airbnb 是如何改进 Listing Embedding 的学习以及其他方面的应用。 (1)正负样本集构建的改进
- 使用 booked listing 作为全局上下文
- booked listing 表示用户在 session 中最终预定的房源,一般只会出现在结束的 session 中。
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
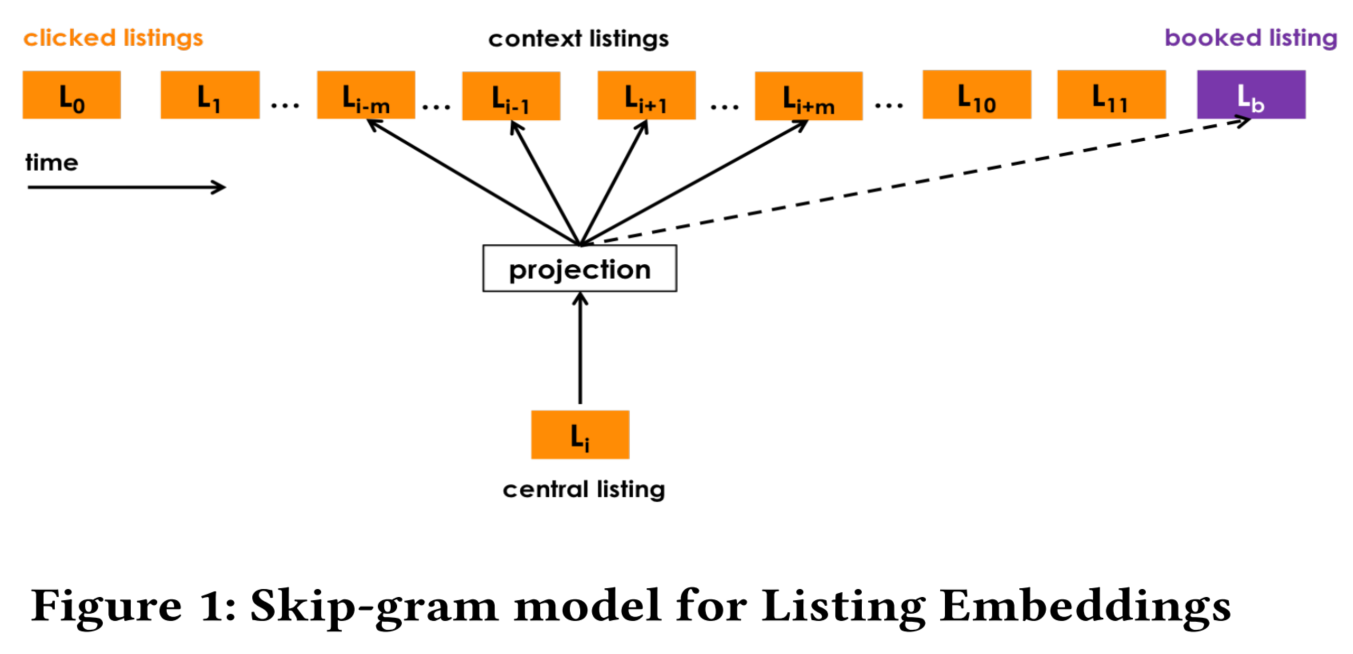
- booked listing 作为全局正样本,故优化的目标函数更新为:
$$ \underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}{p}} \log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime^{\prime}} \mathbf{v}{l}}}+\sum{(l, c) \in \mathcal{D}{n}} \log \frac{1}{1+e^{\mathbf{v}{c}^{\prime} \mathbf{v}{l}}} + \log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime} \mathbf{v}_{l_b}}} $$
- 优化负样本的选择
-
用户通过在线网站预定房间时,通常只会在同一个 market (将要停留区域)内进行搜索。
-
对于用户点击过的样本集 $ \mathcal{D}{p} $ (正样本集)而言,它们大概率位于同一片区域。考虑到负样本集 $ \mathcal{D}{n} $ 是随机抽取的,大概率来源不同的区域。
-
Airbnb 发现这种样本的不平衡,在学习同一片区域房源的 Embedding 时会得到次优解。
-
解决办法也很简单,对于每个滑窗中的中心 lisitng,其负样本的选择新增了与其位于同一个 market 的 listing。至此,优化函数更新如下: $$ \underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}{p}} \log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime^{\prime}} \mathbf{v}{l}}}+\sum{(l, c) \in \mathcal{D}{n}} \log \frac{1}{1+e^{\mathbf{v}{c}^{\prime} \mathbf{v}{l}}} +\log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime} \mathbf{v}{l_b}}} + \sum{(l, m_n ) \in \mathcal{D}{m_n}} \log \frac{1}{1+e^{\mathbf{v}{m_n}^{\prime} \mathbf{v}_{l}}} $$
- $ \mathcal{D}_{m_n} $ 表示与滑窗中的中心 listing 位于同一区域的负样本集。
-
(2)Listing Embedding 的冷启动
- Airbnb 每天都有新的 listings 产生,而这些 listings 却没有 Embedding 向量表征。
- Airbnb 建议利用其他 listing 的现有的 Embedding 来为新的 listing 创建 Embedding。
- 在新的 listing 被创建后,房主需要提供如位置、价格、类型等在内的信息。
- 然后利用房主提供的房源信息,为其查找3个相似的 listing,并将它们 Embedding 的均值作为新 listing 的 Embedding表示。
- 这里的相似,包含了位置最近(10英里半径内),房源类型相似,价格区间相近。
- 通过该手段,Airbnb 可以解决 98% 以上的新 listing 的 Embedding 冷启动问题。
(3)Listing Embedding 的评估 经过上述的两点对 Embedding 的改进后,为了评估改进后 listing Embedding 的效果。
- Airbnb 使用了800万的点击 session,并将 Embedding 的维度设为32。
评估方法包括:
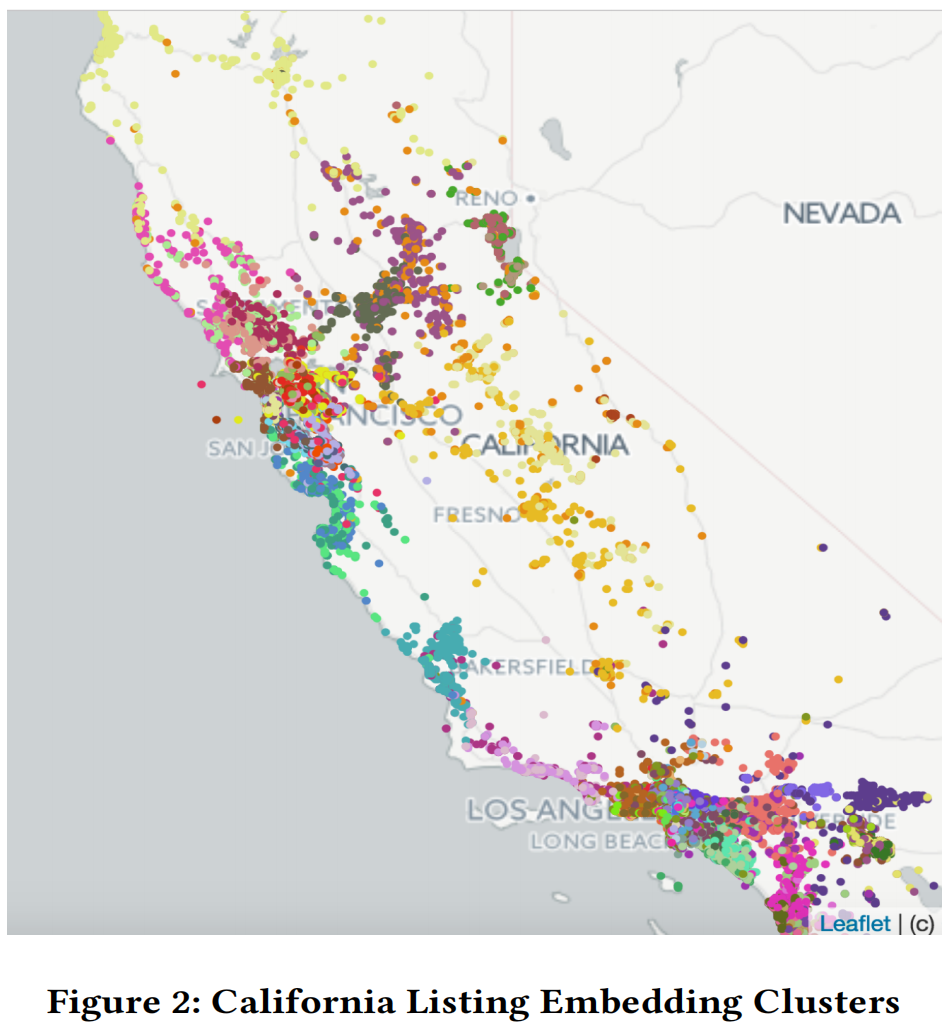
- 评估 Embedding 是否包含 listing 的地理位置相似性。
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
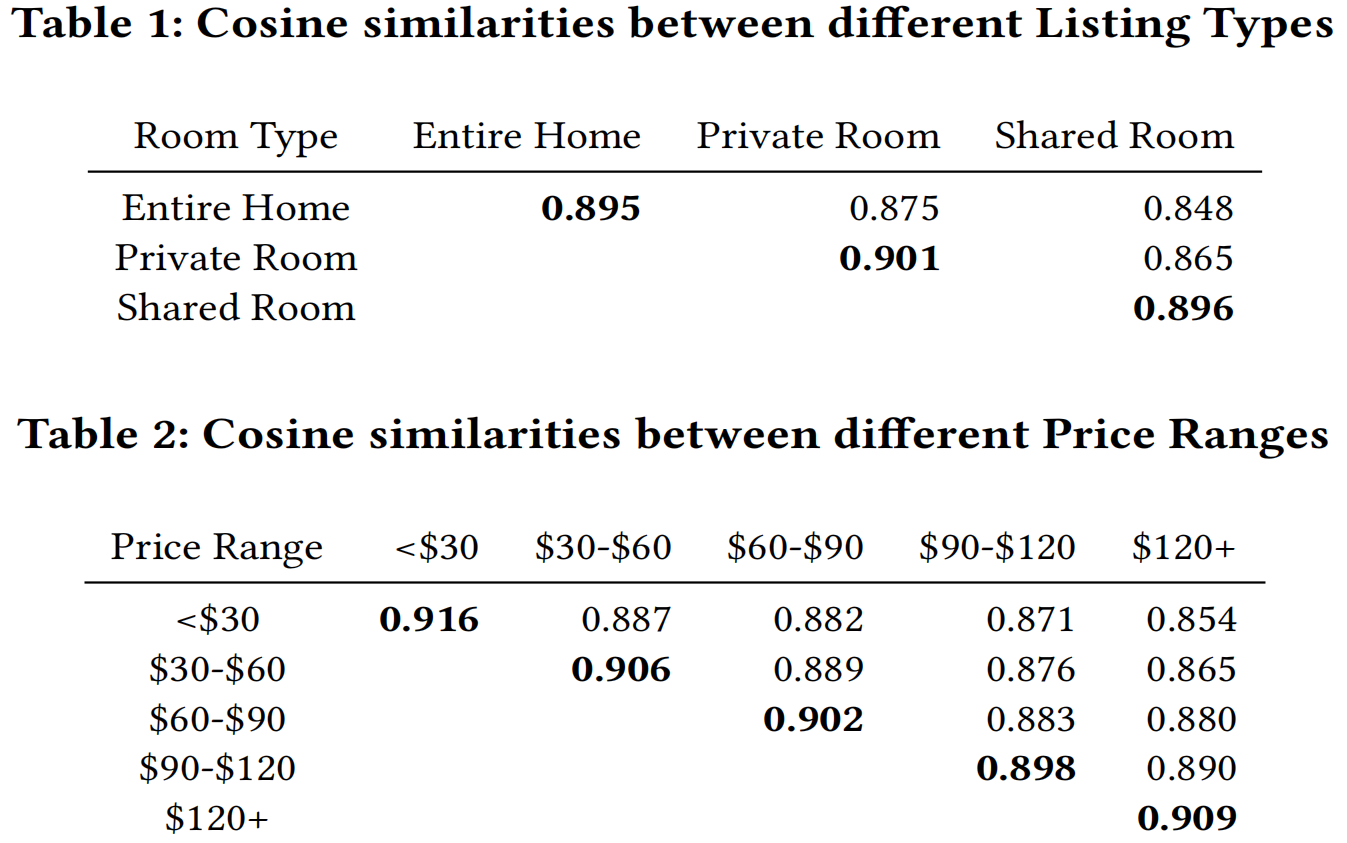
- 评估不同类型、价格区间的房源之间的相似性。
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
- 评估房源的隐式特征
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
- 对于一些隐式信息,例如架构、风格、观感等是无法直接学习。
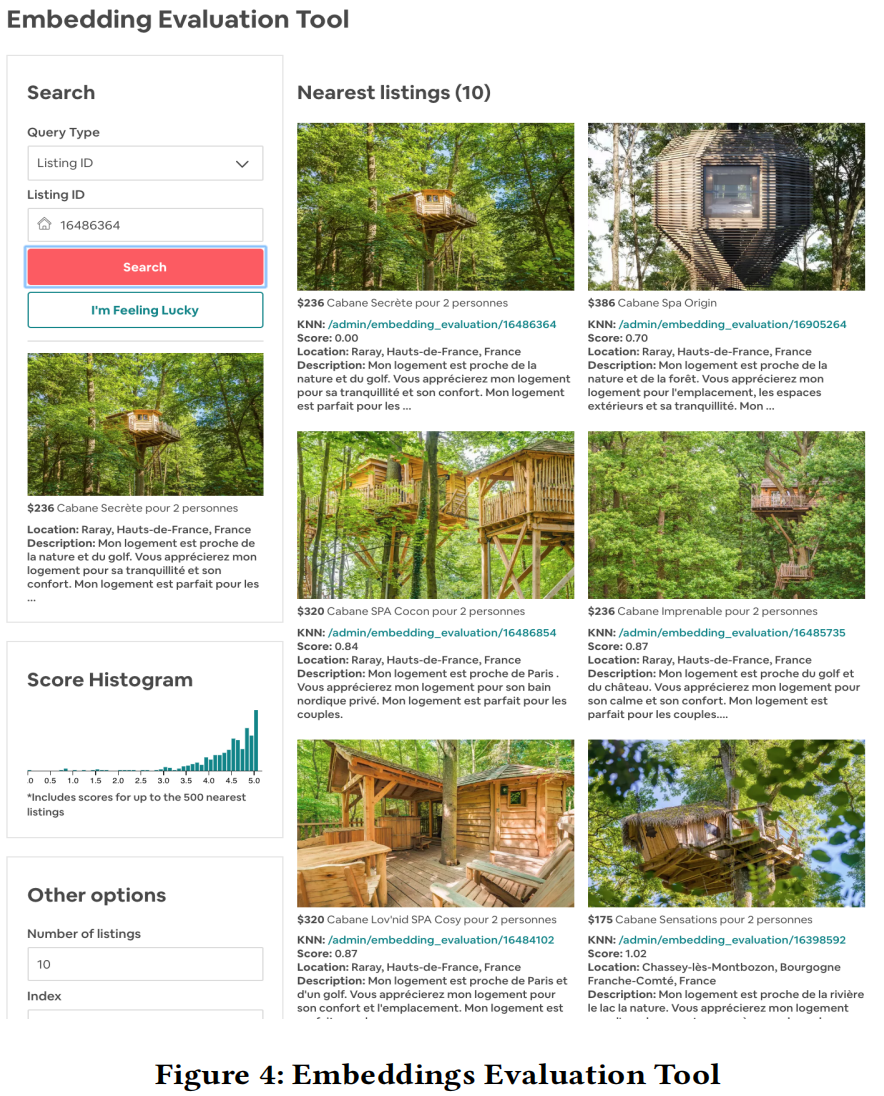
- 为了验证基于 Word2Vec 学习到的 Embedding是否隐含了它们在外观等隐式信息上的相似性,Airbnb 内部开发了一款内部相似性探索工具。
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
前面提到的 Listing Embedding,它是基于用户的点击 sessions 学习得到的。
- 同一个 session 内的点击时间间隔低于30分钟,所以它们更适合短期,session 内的个性化需求。
- 在用户搜索 session 期间,该方法有利于向用户展示与点击过的 listing 更相似的其他 listings 。
Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Listing 的长期兴趣特征表示进行了探索。长期兴趣的探索是有利于 Airbnb 的业务发展。例如,用户当前在洛杉矶进行搜索,并且过去在纽约和伦敦预定过其他房源。那么,向用户推荐与之前预定过的 listing 相似的 listings 是更合适的。
- 长期兴趣的探索是基于 booking session(用户的历史预定序列)。
- 与前面 Listing Embedding 的学习类似,Airbnb 希望借助了 Skip-Gram 模型学习不同房源的 Embedding 表示。
但是,面临着如下的挑战:
- booking sessions $ \mathcal{S}_{b} $ 数据量的大小远远小于 click sessions $ \mathcal{S} $ ,因为预定本身就是一件低频率事件。
- 许多用户过去只预定了单个数量的房源,无法从长度为1的 session 中学习 Embedding
- 对于任何实体,要基于 context 学习到有意义的 Embedding,该实体至少在数据中出现5-10次。
- 但平台上大多数 listing_ids 被预定的次数低于5-10次。
- 用户连续两次预定的时间间隔可能较长,在此期间用户的行为(如价格敏感点)偏好可能会发生改变(由于职业的变化)。
为了解决该问题,Airbnb 提出了基于 booking session 来学习用户和房源的 Type Embedding。给定一个 booking sessions 集合 $ \mathcal{S}_{b} $ ,其中包含了 $ M $ 个用户的 booking session:
- 每个 booking session 表示为: $ s_{b}=\left(l_{b 1}, \ldots, l_{b M}\right) $
- 这里 $ l_{b1} $ 表示 listing_id,学习到 Embedding 记作 $ \mathbf{v}{l{i d}} $
(1)什么是Type Embedding ? 在介绍 Type Embedding 之前,回顾一下 Listing Embedding:
- 在 Listing Embedding 的学习中,只学习房源的 Embedding 表示,未学习用户的 Embedding。
- 对于 Listing Embedding,与相应的 Lisitng ID 是一一对应的, 每个 Listing 它们的 Embedding 表示是唯一的。
对于 Type Embedding ,有如下的区别:
- 对于不同的 Listing,它们的 Type Embedding 可能是相同的(User 同样如此)。
- Type Embedding 包含了 User-type Embedding 和 Listing-type Embedding。
为了更直接快速地了解什么是 Listing-type 和 User-type,举个简单的例子:
- 小王,是一名西藏人,性别男,今年21岁,就读于中国山东的蓝翔技校的挖掘机专业。
- 通常,对于不同的用户(如小王),给定一个 ID 编码,然后学习相应的 User Embedding。
- 但前面说了,用户数据过于稀疏,学习到的 User Embedding 特征表达能力不好。
- 另一种方式:利用小王身上的用户标签,先组合出他的 User-type,然后学习 Embedding 表示。
- 小王的 User-type:西藏人_男_学生_21岁_位置中国山东_南翔技校_挖掘机专业。
- 组合得到的 User-type 本质上可视为一个 Category 特征,然后学习其对应的 Embedding 表示。
下表给出了原文中,Listing-type 和 User-type 包含的属性及属性的值:
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
- 一个来自 US 的 Entire Home listing(lt1),它是一个二人间(c2),1 床(b1),一个卧室(bd2),1 个浴室(bt2),每晚平均价格为 60.8 美元(pn3),每晚每个客人的平均价格为 29.3 美元(pg3),5 个评价(r3),所有均 5 星好评(5s4),100% 的新客接受率(nu3)。
- 因此该 listing 根据上表规则可以映射为:Listing-type = US_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3。
(2)Type Embedding 的好处 前面在介绍 Type Embedding 和 Listing Embedding 的区别时,提到过不同 User 或 Listing 他们的 Type 可能相同。
- 故 User-type 和 Listing-type 在一定程度上可以缓解数据稀疏性的问题。
- 对于 user 和 listing 而言,他们的属性可能会随着时间的推移而变化。
- 故它们的 Embedding 在时间上也具备了动态变化属性。
(3)Type Embedding 的训练过程 Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要注意:
-
联合训练 User-type Embedding 和 Listing-type Embedding
-
如下图(a),在 booking session 中,每个元素代表的是 (User-type, Listing-type)组合。
- 为了学习在相同向量空间中的 User-type 和 Listing-type 的 Embeddings,Airbnb 的做法是将 User-type 插入到 booking sessions 中。
- 形成一个(User-type, Listing-type)组成的元组序列,这样就可以让 User-type 和 Listing-type 的在 session 中的相对位置保持一致了。
-
User-type 的目标函数: $$ \underset{\theta}{\operatorname{argmax}} \sum_{\left(u_{t}, c\right) \in \mathcal{D}{b o o k}} \log \frac{1}{1+e^{-\mathbf{v}{c}^{\prime} \mathbf{v}{u{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}{n e g}} \log \frac{1}{1+e^{\mathbf{v}{c}^{\prime} \mathbf{v}{u{t}}}} $$
- $ \mathcal{D}{\text {book }} $ 中的 $ u_t $ (中心词)表示 User-type, $ c $ (上下文)表示用户最近的预定过的 Listing-type。 $ \mathcal{D}{\text {neg}} $ 中的 $ c $ 表示 negative Listing-type。
- $ u_t $ 表示 User-type 的 Embedding, $ \mathbf{v}_{c}^{\prime} $ 表示 Listing-type 的Embedding。
-
Listing-type 的目标函数: $$ \begin{aligned} \underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}{c}^{\prime} \mathbf{v}{l{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}{c}^{\prime} \mathbf{v}{l{t}}}} \ \end{aligned} $$
- 同理,不过窗口中的中心词为 Listing-type, 上下文为 User-type。
-
-
Explicit Negatives for Rejections
-
用户预定房源以后,还要等待房源主人的确认,主人可能接受或者拒绝客人的预定。
- 拒接的原因可能包括,客人星级评定不佳,资料不完整等。
-
前面学习到的 User-type Embedding 包含了客人的兴趣偏好,Listing-type Embedding 包含了房源的属性特征。
- 但是,用户的 Embedding 未包含更容易被哪类房源主人拒绝的潜语义信息。
- 房源的 Embedding 未包含主人对哪类客人的拒绝偏好。
-
为了提高用户预定房源以后,被主人接受的概率。同时,降低房源主人拒绝客人的概率。Airbnb 在训练 User-type 和 Listing-type 的 Embedding时,将用户预定后却被拒绝的样本加入负样本集中(如下图b)。
-
更新后,Listing-type 的目标函数: $$ \begin{aligned} \underset{\theta}{\operatorname{argmax}} & \sum_{\left(u_{t}, c\right) \in \mathcal{D}{b o o k}} \log \frac{1}{1+\exp ^{-\mathbf{v}{c}^{\prime} \mathbf{v}{u{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}{n e g}} \log \frac{1}{1+\exp ^{\mathbf{v}{c}^{\prime} \mathbf{v}{u{t}}}} \ &+\sum_{\left(u_{t}, l_{t}\right) \in \mathcal{D}{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}{{l_{t}}}^{\prime} \mathrm{v}{u{t}}}} \end{aligned} $$
-
更新后,User-type 的目标函数: $$ \begin{aligned} \underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}{c}^{\prime} \mathbf{v}{l{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}{c}^{\prime} \mathbf{v}{l{t}}}} \ &+\sum_{\left(l_{t}, u_{t}\right) \in \mathcal{D}{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}^{\prime}{u_{t}} \mathrm{v}{l{t}}}} \end{aligned} $$
-
-

前面介绍了两种 Embedding 的生成方法,分别为 Listing Embedding 和 User-type & Listing-type Embedding。本节的实验部分,将会介绍它们是如何被使用的。回顾 Airbnb 的业务背景,当用户查看一个房源时,他们有两种方式继续搜索:返回搜索结果页,或者查看房源详情页的「相似房源」。
在给定学习到的 Listing Embedding,通过计算其向量 $ v_l $ 和来自同一区域的所有 Listing 的向量 $ v_j $ 之间的余弦相似度,可以找到给定房源 $ l $ 的相似房源。
- 这些相似房源可在同一日期被预定(如果入住-离开时间已确定)。
- 相似度最高的 $ K $ 个房源被检索为相似房源。
- 计算是在线执行的,并使用我们的分片架构并行进行,其中部分 Embedding 存储在每个搜索机器上。
A/B 测试显示,基于 Embedding 的解决方案使「相似房源」点击率增加了21%,最终通过「相似房源」产生的预订增加了 4.9%。
Airbnb 的搜索排名的大致流程为:
- 给定查询 $ q $ ,返回 $ K $ 条搜索结果。
- 基于排序模型 GBDT,对预测结果进行排序。
- 将排序后的结果展示给用户。
(1)Query Embedding 原文中似乎并没有详细介绍 Airbnb 的搜索技术,在参考的博客中对他们的 Query Embedding 技术进行了描述。如下:
Airbnb 对搜索的 Query 也进行了 Embedding,和普通搜索引擎的 Embedding 不太相同的是,这里的 Embedding 不是用自然语言中的语料库去训练的,而是用 Search Session 作为关系训练数据,训练方式更类似于 Item2Vec,Airbnb 中 Queue Embedding 的一个很重要的作用是捕获用户模糊查询与相关目的地的关联,这样做的好处是可以使搜索结果不再仅仅是简单地进行关键字匹配,而是通过更深层次的语义和关系来找到关联信息。比如下图所示的使用 Query Embedding 之前和之后的两个示例(Airbnb 非常人性化地在搜索栏的添加了自动补全,通过算法去 “猜想” 用户的真实目的,大大提高了用户的检索体验)
(2)特征构建 对于各查询,给定的训练数据形式为: $ D_s = \left(\mathbf{x}{i}, y{i}\right), i=1 \ldots K $ ,其中 $ K $ 表示查询返回的房源数量。
- $ \mathbf{x}_{i} $ 表示第 $ i $ 个房源结果的 vector containing features:
- 由 listing features,user features,query features 以及 cross-features 组成。
- $ y_{i} \in{0,0.01,0.25,1,-0.4} $ 表示第 $ i $ 个结果的标签。
- $ y_i=1 $ 表示用户预定了房源,..., $ y_i=-0.4 $ 表示房主拒绝了用户。
下面,介绍 Airbnb 是如何利用前面的两种种 Embedding 进行特征构建的。
- 如果用一句话来概括,这些基于 Embedding 的构建特征均为余弦相似度。
- 新构建的特征均为样本 $ \mathbf{x}_{i} $ 特征的一部分。
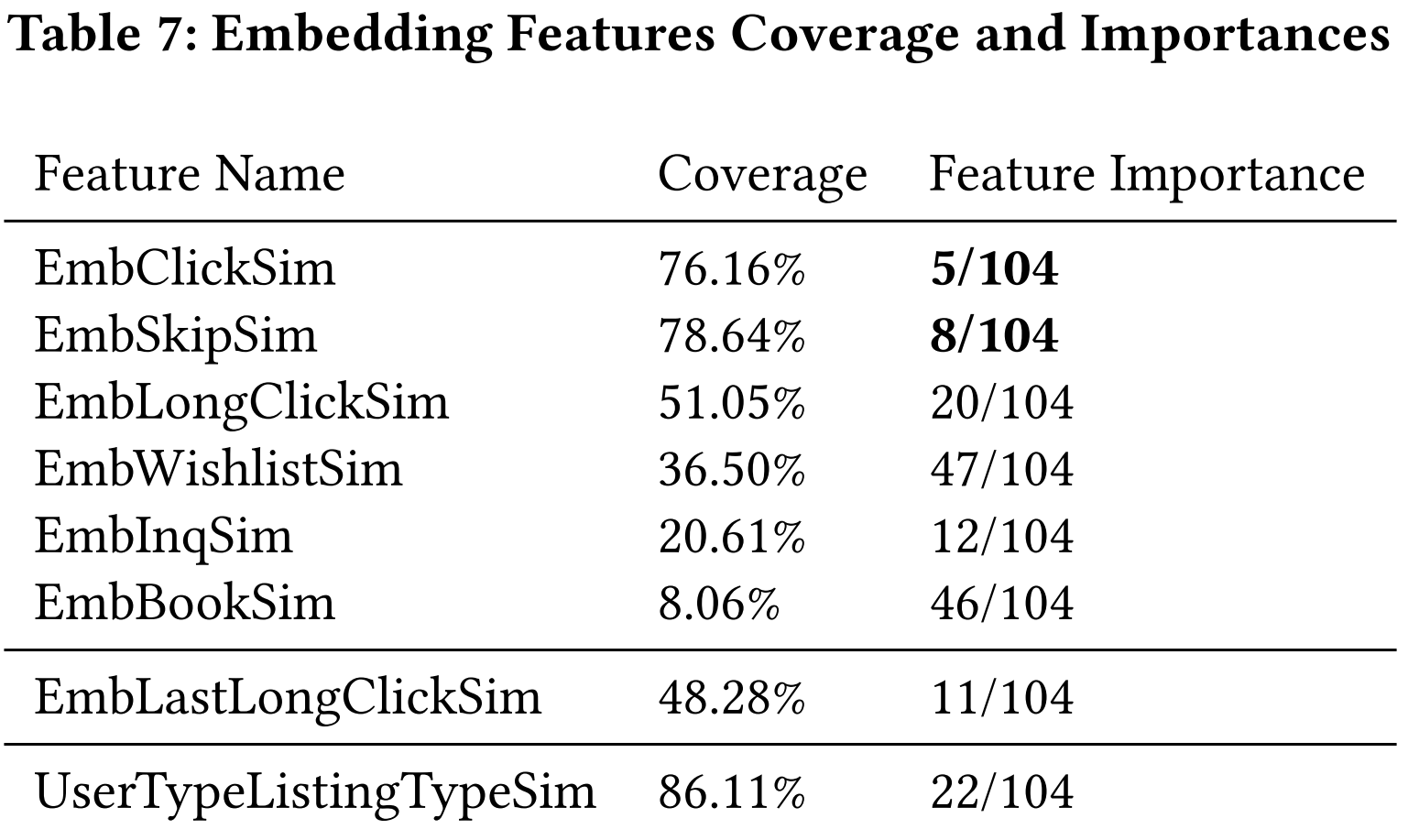
构建的特征如下表所示:
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。

① 基于 Listing Embedding Features 的特征构建
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:

-
对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
-
假如 $ H_c $ 包含了 New YorK 和 Los Angeles 两个 market 的点击记录,则划分为 $ H_c(NY) $ 和 $ H_c(LA) $ 。
-
计算候选房源和不同行为之间的相似度。
-
上述6种行为对应的相似度特征计算方式是相同的,以 $ H_c $ 为例: $$ \operatorname{EmbClickSim}\left(l_{i}, H_{c}\right)=\max {m \in M} \cos \left(\mathbf{v}{l_{i}}, \sum_{l_{h} \in m, l_{h} \in H_{c}} \mathbf{v}{l{h}}\right) $$
-
其中, $ M $ 表示 market 的集合。第二项实际上为 Centroid Embedding(Embedding 的均值)。
-
-
-
除此之外,Airbnb 还计算了候选房源的 Embedding 与 latest long click 的 Embedding 之间的余弦相似度。 $$ \operatorname{EmbLastLongClickSim }\left(l_{i}, H_{l c}\right)=\cos \left(\mathbf{v}{l{i}}, \mathbf{v}{l{\text {last }}}\right) $$
② 基于 User-type & Listing-type Embedding Features 的特征构建
-
对于候选房源 $ l_i $ ,先查到其对应的 Listing-type $ l_t $ ,再找到用户的 User-type $ u_t $ 。
-
最后,计算 $ u_t $ 与 $ l_t $ 对应的 Embedding 之间的余弦相似度: $$ \text { UserTypeListingTypeSim }\left(u_{t}, l_{t}\right)=\cos \left(\mathbf{v}{u{t}}, \mathbf{v}{l{t}}\right) $$
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
(3)模型 特征构建完成后,开始对模型进行训练。
- Airbnb 在搜索排名中使用的是 GBDT 模型,该模型是一个回归模型。
- 模型的训练数据包括数据集 $ \mathcal{D} $ 和 search labels 。
最后,利用 GBDT 模型来预测线上各搜索房源的在线分数。得到预测分数后,将按照降序的方式展现给用户。